 | |
| VISTA DEL PUERTO DE ERJOS EN LA CONFLUENCIA ENTRE LAS PRIMERAS ESTRIBACIONES DEL MACIZO DE TENO, AL NOROESTE DE TENERIFE, Y EL VALLE DE SANTIAGO, AL OESTE, CON EL TEIDE AL FONDO. |
Lo primero que tenemos que plantearnos, aunque parezca una obviedad, es lo que debemos entender por archivo externo desde la perspectiva de Python. Pues bien: consideramos como archivo externo a Python todo aquél cuya extensión no sea .py y sus extensiones relacionadas o asociadas (.pym, .pyc, .pypi, etc.), esto es, cualquier archivo con extensión, por ejemplo, .txt, que apunta a un archivo de texto plano generado con el socorrido bloc de notas; .pdf, para los archivos digitales portátiles; .doc, para los textos generados desde Microsoft Word; .jpg, .png, .gif y otros más para archivos de imagen; .avi, .mpg, .mkv, etc. para vídeo; .mp3, .wav, .ogg, etc. para audio; y muchos más que ni siquiera Dios sabe que existen.
Algunos de estos archivos externos pueden ser generados por el propio Python con el propósito de preservar los datos devueltos por la ejecución de un programa, vamos, que no se pierdan en el limbo de los justos cuando cerramos una sesión. ¡Voilà! Acabamos de descubrir el concepto de PERSISTENCIA DE DATOS o PERSISTENCIA DE LA INFORMACIÓN. Entendemos por PERSISTENCIA el proceso por el cual uno o más datos (información) obtenida como resultado de la ejecución de un programa, se conserva y es posible recuperar una vez hayamos cerrado la sesión, al cabo de un segundo, de una hora , de un día, de un año, de un siglo, de mil. Así la información quedará almacenada para ser re-utilizada por el mismo programa o por cualquier otro.

PYTHON DISPONE DE DOS MODOS DE ALMACENAR INFORMACIÓN PARA SU POSTERIOR REUTILIZACIÓN Y GARANTIZAR ASÍ SU PERSISTENCIA. POR UN LADO, A TRAVÉS DE LOS ARCHIVOS EXTERNOS QUE ACABAMOS DE MENCIONAR Y DONDE LOS DATOS OBTENIDOS NO PUEDEN RECUPERARSE PARA OPERAR CON ELLOS EN LOS PROGRAMAS Y, POR OTRO, A TRAVÉS DE BASES DE DATOS, BBDD, QUE SÍ PERMITEN SU REUTILIZACIÓN EN NUESTROS PROGRAMAS.
UNA SALCHICHITA DE POLLO... ¿NO?
Veámoslo en este esquema:

En el esquema hemos optado por poner de ejemplo un archivo *.txt de texto plano porque es el más sencillo y básico de construir y manipular. Vamos con ello.
Veamos cuál es el procedimiento para insertar datos en un archivo externo:
CREACIÓN → APERTURA→ MANIPULACIÓN DEL ARCHIVO → CIERRE
Existen dos maneras aunque, realmente, en última instancia viene a ser la misma: todo se basa en la función open(). Ahora bien, podemos llamarla desde la librería estándar donde Python la guarda bien calentita, usando una importación parcial o relativa, del modo siguiente: from io import open. O bien podemos hacerlo directamente invocándola como una función preconstruida: open(). En ambos casos el resultado es el mismo. Su uso nos permite manejar el stream, la retransmisión de datos desde un data búfer, para facilitar flujos de datos bidireccionales desde el propio programa hacia el exterior y viceversa (leemos datos almacenados, escribimos más datos, volvemos a leer los datos originales más los que acabamos de añadir, volvemos a escribir, volvemos a leer; sobreescrituras dinámicas, etc.).

La mayoría de los argumentos opcionales que podemos manipular en la función los podemos dejar así, tal cual están, con sus valores predefinidos. Los que realmente nos interesan, para su uso más básico y habitual, son, evidentemente, el primero, file, donde pasamos una string, una cadena de texto, con la ruta (path) y el nombre del fichero y su extensión correspondiente, normalmente, .txt, para trabajar con textos planos; mode, que especifica el modo de apertura del fichero, esto es, lo que queremos hacer con él; y encoding, al que deberíamos dar siempre el valor "utf-8" si no queremos pasar dolores de cabeza y jaquecas varias.
Sobre este último asunto, observemos el siguiente ejemplo:

Vemos como, por defecto, Python tiene un sistema propio de codificación de archivos, de encoding, que es cp1252. Pues, posiblemente, con esta codificación por defecto vamos a ver lo mismo que un ciego con gafas de sol a medianoche, en mitad del campo y con luna nueva. Mejor le cambiamos la codificación a "utf-8", como se muestra al final del ejemplo y respiramos tranquilos.
Con el argumento file, pueden pasar dos cosas: una, que si el fichero no existe se cree al instante como por arte de magia; dos, si el fichero ya ha sido creado previamente, podamos abrirlo y ver su contenido, añadir cosas, reescribir, etc. En ambos casos, el fichero se creará en la carpeta que pasemos como path o, lo localizaremos para manipularlo en la ruta donde esté almacenado.

¡CUIDADO! EN WINDOWS, PYTHON NO LEE LAS RUTAS (PATHS) CON LA SINTAXIS PROPIA DEL SISTEMA OPERATIVO, SINO QUE TIENE SU PROPIA FORMA DE HACERLO. AFORTUNADAMENTE, SÓLO AFECTA A LA DIRECCIÓN DE LAS BARRAS DELIMITADORAS. MIRAD ABAJO:
 Vamos a por los modos (mode). Ya hemos dicho que mode atiende a lo que queremos (o podemos) hacer con los archivos de texto. Mostramos la siguiente tabla.
Vamos a por los modos (mode). Ya hemos dicho que mode atiende a lo que queremos (o podemos) hacer con los archivos de texto. Mostramos la siguiente tabla.

Para crear un fichero que, por cierto, de no existir previamente, es lo primero que tenemos que hacer para poder realizar el resto de operaciones (somos programadores, no magos), podemos declarar una variable que almacene el resultado de la lectura de la función open(). Como primer argumento, obligatorio, de la función, pasamos como cadena de texto, es decir, entre comillas, un nombre de archivo, el que queramos, el que más nos guste, con su correspondiente extensión .txt. Como segundo argumento debemos indicar el modo (mode) en que queremos abrir el archivo y que, también, debemos pasar como cadena de texto. Recordemos que de modo predeterminado, el modo de la función es de lectura, "r", por lo que tendremos que modificar el valor de la propiedad, bien a "w", para crear/escribir nuestro archivo como tal; o bien "wb", si vamos a crear/escribir un archivo en codificación binaria. Por cierto, no es necesario escribir la propiedad (mode="w"): nos basta con escribir el valor a secas.
Vemos un ejemplo:

Podemos observar en la sección superior, que se corresponde con la codificación Python en el IDLE, que hemos llamado a una importación parcial de la función open() desde el módulo io de la librería estándar de Python aunque, como ya hemos dicho y volvemos a recordar aquí, podemos acceder directamente a la función open() sin necesidad de importaciones, por cortesía del intérprete.
A continuación, declaramos una variable, textfile, a la que asignamos la función open() y a la que pasamos dos argumentos: el nombre de archivo que queremos con su correspondiente extensión .txt, "file.txt", y el modo "w" (fijémonos que hemos prescindido de incluir el nombre de la propiedad) para crear el archivo.
Con lo que acabamos de hacer, ya tenemos un archivo de texto en blanco preparado para insertar en él todo el texto que queramos.
¿Y cómo lo hacemos?
Muy fácil. Podemos declarar una variable, dato, en el ejemplo, y asignarle, obviamente como string, el texto que queramos. A continuación llamamos a la variable que almacena la función, textfile, y por la sintaxis del punto, le pasamos el método write() que, como su nombre indica (to write=escribir), nos permitirá escribir aquéllo que le pasemos como argumento sobre nuestro archivo recién creado, blanco e inmaculado. Si queremos, podemos pasarle directamente una string, quizás más cómodo según para qué, pero también menos plástico.
Observemos que se nos devuelve un número: 47, en el ejemplo. ¡Anda! ¿Y ésto? Obedece a que la ejecución de la función devuelve por defecto el número de caracteres de la cadena, esto es, su tamaño, como podemos confirmar si le aplicamos la función len().

* IMPORTANTE: Siempre que creemos o abramos un fichero, cuando hayamos terminado de operar con él, debemos cerrar sesión mediante el método close() que aplicamos a la variable que almacena a la función mediante la sintaxis de punto. Por lo pronto, nos permite liberar recursos de nuestro pc, sobre todo, memoria caché. Pero lo más importante es que consigue que la información que vamos introduciendo en el fichero, de facto, virtual, sólo en el momento de cierre, se "formaliza", se imprime y se nos hace visible, negro sobre blanco, en nuestro fichero, como podemos comprobar en la sección inferior del ejemplo. Aquí, en el encabezado, podemos ver que lo hemos abierto en el bloc de notas de Windows así como el nombre, "file", que le dimos en el momento de su creación. La impresión en un fichero abierto en modo "w", por defecto, se realiza siempre desde la esquina superior izquierda del lienzo, que se corresponde con la posición inicial del prompt de escritura (la barrita vertical parpadeante). Como cuando construimos nuestro texto usamos una expresión regular para el salto de línea, \n, entre medio y que ya hemos empleado en otras ocasiones, en el archivo de texto se nos muestra dos líneas de texto.

TENGAMOS SIEMPRE EN CUENTA QUE CADA VEZ QUE USAMOS EL MODO "w" DE ESCRITURA PARA CREAR UN ARCHIVO, SI ÉSTE YA EXISTE (EL NOMBRE QUE LE PASAMOS COMO PRIMER ARGUMENTO DE LA FUNCIÓN YA EXISTE EN EL DIRECTORIO EN EL QUE ESTAMOS TRABAJANDO CON LA MISMA EXTENSIÓN .txt), PYTHON SITUARÁ EL PROMPT DE ESCRITURA DE NUEVO EN EL ÁNGULO SUPERIOR IZQUIERDO Y SOBREESCRIBIRÁ TODA LA INFORMACIÓN QUE HAYAMOS ESCRITO PREVIAMENTE EN EL ARCHIVO, SUSTITUYÉNDOLA POR LA NUEVA. ¡NO DIGÁIS QUE NO OS LO HE ADVERTIDO!
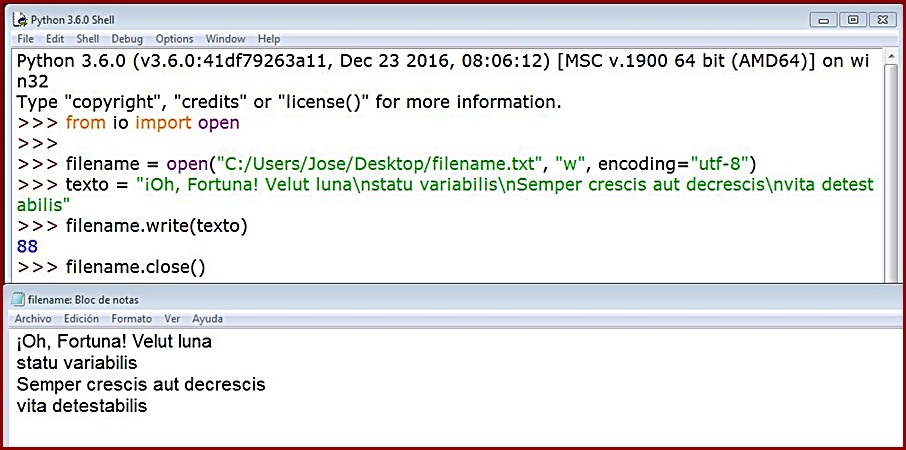
Cuando abramos un archivo de texto, tanto para crearlo por primera vez, para sobreescribir su contenido, si eso es lo que queremos, como para añadir más texto, sería una buena, una muy buena idea, para evitarnos sorpresas a posteriori, recurrir a la propiedad encoding y darle el valor "utf-8", para que codifique nuestro texto en este formato, perfectamente legible para nosotros como vemos en el ejemplo que sigue:

Observemos que hemos pasado una ruta, un path, como primer argumento de la función, con el nombre de archivo y su extensión al final. Esto lo hacemos para conseguir que nuestro fichero se almacene en una carpeta o directorio de nuestra elección, y no necesariamente en la carpeta del programa (podemos localizarlo arriba, a la izquierda, sobre el fondo negro del salvapantallas). También hemos optado por introducir directamente el texto como argumento de write(). Pero lo que realmente importa es que hemos introducido en la zona de argumentos de open() la propiedad encoding="utf-8". En la sección inferior vemos el resultado.
Vemos otro ejemplo similar:

Para evitar un borrado incidental de un fichero de texto previamente creado, Python nos provee del modo "x" que usaremos en lugar de "w". ¿Qué ocurre si usamos "x" en lugar de "w"? Que en el flujo de lectura, si el intérprete de Python encuentra que el nombre de fichero que le hemos pasado a la función open() ya existe, detiene automáticamente la ejecución y lanza una excepción de tipo FileExistsError como un castillo. Recordemos que podemos gestionar las excepciones para obtener las lecturas adecuadas a nuestros intereses como programadores (v. TRATAMIENTO DE EXCEPCIONES). En consecuencia, "x" aborda la creación exclusiva de un fichero, por lo demás, con un comportamiento similar al de "w".


Aún nos queda por ver dos modos más de escritura:
El modo "a" permite la apertura de un fichero de texto preexistente en modo add (to add=añadir). Como su nombre indica, nos permite adicionar, agregar, añadir más texto a un contenido ya existente. Y lo hace porque, contrariamente al comportamiento de "w", que sitúa el cursor siempre al comienzo del lienzo provocando el borrado de todo el texto preexistente (sobreescritura, recordemos) , el modo "a" lo sitúa justo a continuación del último carácter del texto, permitiéndonos añadir texto a partir de aquí, pero no hace un salto de línea. Por este motivo, si queremos añadir más texto al mismo párrafo, debemos dejar un espacio en blanco para que los caracteres no se junten, que queda feo; y si por el contrario queremos iniciar un párrafo nuevo, aparte, comenzar con un salto de línea, "\n", para asegurarnos que el párrafo se muestre en un bloque distinto al anterior.
Tengamos en cuenta que el carácter escape "\n" se puede colocar al principio de una cadena para escribir debajo de ésta, y/o al final, para que cualquier texto posterior se escriba debajo, en una nueva línea.
Sin embargo, con estas cosas nuestro Python se vuelve un poquito quisquilloso: lo que acabamos de decir es válido si pasamos el texto directamente como argumento de la función write(), porque si asignamos el texto a una variable y, luego, pasamos ésta como argumento de la función write(), el intérprete de Python no lo va a tener en cuenta.

PODEMOS ESTABLECER SALTOS DE LÍNEA MÁS AMPLIOS QUE EL TAMAÑO DE UNA SIMPLE LÍNEA CON ALGORITMOS COMO ("\n" * 5), QUE INTERPONDRÁ 5 LÍNEAS ENTRE EL FINAL DE UN PÁRRAFO Y EL COMIENZO DEL OTRO.
Vamos a verlo en los ejemplos siguientes.


Finalizamos los modos de escritura con el híbrido "r+" que permite al mismo tiempo leer y escribir de cara a actualizar un fichero: "r+" ⟶ Actualización. La apertura de un fichero en este modo nos permite leerlo y, a la vez, escribir datos en él. Se realiza una sobreescritura en lugar de una simple inserción de texto. Además, sitúa el cursor de escritura justo a continuación del último carácter que hayamos escrito de modo que, si estamos al final del fichero, se comporta de modo análogo a "a". Veámoslo:

Vamos a imaginarnos que tenemos el siguiente texto creado con el modo "w" de escritura de ficheros:







Nos podemos apoyar en nuestra función amiga len() si se nos antoja colocar el prompt en una posición determinada del texto, bien fuera la mitad, un cuarto o un tercio del mismo. Veamos un ejemplo a continuación que nos permite leer a partir de la cuarta parte de un texto dado:

También podemos usar seek() para leer a partir de una línea determinada, para lo que deberíamos utilizar la función readlines(). Así que para saber de qué va esto de seek() comencemos por saber de qué va readlines(). O, aún mejor, readline(), ¡ojo!, 🙋, sin 's' al final.


Podemos invocar de manera sucesiva al método readline() para ir leyendo las diferentes líneas de acuerdo a su distribución sobre el texto, de arriba a abajo.

Contamos con la opción de recurrir a un bucle for/in y considerar nuestro archivo de texto como un iterable, de manera que el método lo recorra como una secuencia, devolviendo como resultado un texto mejor estructurado para su lectura.

Así da gusto, ¿Verdad? 👏
Cuando llegamos al final de un texto, devolverá una cadena vacía.
Teniendo esto en cuenta, podemos igualmente recurrir a un loop while con un resultado similar al que conseguimos con el bucle for/in:

Recordemos cerrar siempre los archivos abiertos con el método close() que, recordemos, cierra un archivo previamente abierto (aunque parezca de perogrullo, esto hay que dejarlo claro). Si tuviésemos un archivo para escritura abierto, desecharía cualquier otro texto que no hubiéramos guardado previamente. Lo vemos con un ejemplo aplicado aprovechando un ejemplo de readline().



LECTURA DE UN NÚMERO DADO DE CARACTERES:
Hablamos de un procedimiento que nos permite controlar el uso de memoria en el momento de leer un fichero de texto, y mostrar sólo una cantidad de texto específico según el número de caracteres total, o el espacio que dispongamos en nuestro programa para mostrar texto. Esto equivale a un "paquete" de memoria concreto. Para conseguirlo pasamos el número de bytes que consideremos oportuno como argumento de la función read().

En el ejemplo vemos que las devoluciones son cadenas de texto, string, con un tamaño o longitud (len()) acorde al argumento. Como vemos en 1., son sumativas, es decir, si pedimos un primer tamaño de x caracteres, al momento de pedir una segunda cadena con un tamaño especificado de n caracteres, éste comienza a contar a partir de x. Cuando no hayan más caracteres que mostrar, como en 2., se mostrarán cadenas vacías.
Los valores asumibles por el parámetro punto de partida, por su parte, dependen del resultado de la ejecución de la función asociada tell(), que nos devuelve la posición de lectura/escritura del fichero en cuestión. El tipo de dato que devuelve, bien puede ser un entero, si el fichero se abre en modo texto; o bytes, si se abre en modo binario. En cualquiera de los dos casos se nos remite a una posición específica dentro del fichero, posición que no es estrictamente asimilable a una secuencia de caracteres prototipo, lo que abunda en un cierto grado de arbitrariedad que afecta a la función seek(), que sólo permite ejecutar desplazamientos relativos al inicio del fichero de texto, y con un comportamiento similar a cómo se disponen los ítems en un diccionario, si antes no se filtra por la función tell() cuya devolución determina los valores que puede asumir seek().
Una vez que lo hemos hecho, pulsamos enter y se nos abre el siguiente display en la pantalla de nuestro pc:

1. Es una ventana (ventana gráfica) que se abre por defecto cada vez que trabajamos con Tkinter como paquete destinado al desarrollo GUI (Graphic User Interface), donde veríamos el resultado de nuestros códigos siempre y cuando estuviéramos trabajando con Tkinter en modo gráfico. Como este no es el caso, podemos eliminarla clicando sobre la x, en el extremo superior derecho, minimizarla o arrastrarla fuera de nuestro área de trabajo.
2. Ventana informativa de carpetas y directorios de Python que se corresponde con la ventana actual del sistema, y que nos permite apuntar a cualquier archivo que tengamos almacenado en ella. Por defecto, muestra la carpeta matriz de sistema (Python34, en el ejemplo. Lo podemos ver en el campo de texto: Buscar en:, en la parte superior. Muestra la carpeta de la versión actual de Python en la que estemos trabajando), donde podremos llamar al archivo que queramos. En nuestro caso, en el ejemplo, iremos al escritorio (accederemos a él, de manera sencilla, pulsando sobre el icono correspondiente, a la izquierda de la ventana), donde ya tenemos preparado un archivo de texto sobre el que trabajar.
3. La ventana del IDLE, con el código que hemos introducido hasta el momento, a la espera de continuar.

Seleccionamos el fichero que nos interesa.

Y hacemos doble clic sobre él para que, automáticamente, se muestre su ruta de acceso (path) en el shell.

Sólo hemos mantenido la ventanita del Tkinter para comprobar que podemos arrastrarla y colocarla donde queramos sin que desempeñe papel alguno en el proceso de apertura de un fichero de texto. Como nos es del todo irrelevante, la eliminaremos sin más.
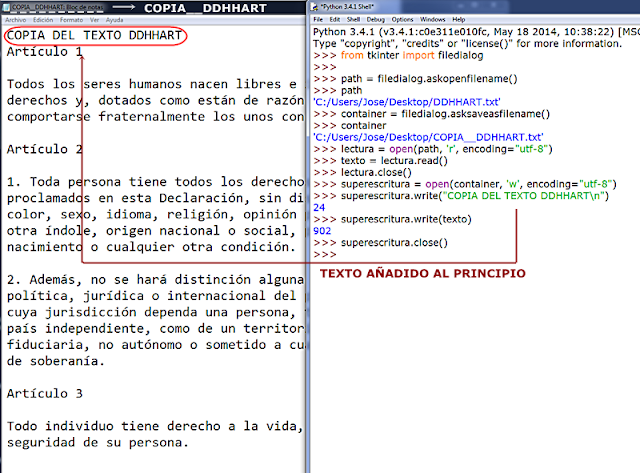
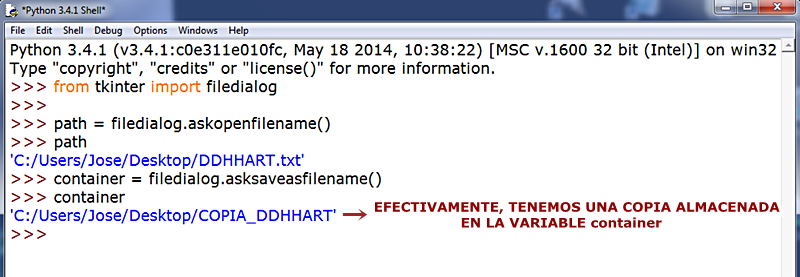
Para clarificar mejor el proceso, volvemos al principio de nuestro código y, tras las importaciones, guardamos en una variable la ruta (path) que nos proporciona el método askopenfilename(), tal cual vemos a continuación:

Comprobaremos que, en efecto, nuestra variable path contiene la ruta devuelta por el método:

Seguidamente, declaramos una segunda variable donde almacenaremos el resultado de la aplicación de un método nuevo de filedialog que llamaremos a continuación: asksaveasfilename(), que guarda (to save) como un nombre de archivo (as filename) una copia del archivo que hemos seleccionado, DDHHART.txt:

Cuando pulsamos enter se nos volverán a abrir las ventanitas de marras pero, en esta ocasión, en la ventana de directorios. En la parte inferior, en el campo de texto correspondiente a NOMBRE:, escribiremos aquél que queramos darle a nuestra copia del archivo:



AUNQUE NO ES NECESARIO, SÍ ES CONVENIENTE AÑADIR LA EXTENSIÓN DE ARCHIVO CORRESPONDIENTE, EN NUESTRO CASO, .txt. PARA NUESTRO EJEMPLO, HEMOS SELECCIONADO EL NOMBRE DE ARCHIVO COPIA_DDHHART.txt.
Hacemos la prueba y, efectivamente, tenemos la copia guardada en su variable.

Ya tenemos los dos archivos: el original, DDHHART.txt, y su copia, COPIA_DDHHART.txt.
Vamos a proceder, pues, a su lectura. Para hacerlo primero tenemos que abrirlo con la función nativa que ya conocemos sobradamente: open(), y que almacenaremos en una variable que declararemos ad hoc. Sobre ésta, aplicaremos correlativamente el método de lectura, read() y, después, el de cierre, close(). Recordemos una vez más que constituye una buena práctica instruir la función de cierre de archivo para evitar sobrecargas innecesarias en la memoria del programa.

Ahora, toca abrir el archivo en el que vamos a escribir, de nuevo, claro está, con la función open() pero, eso sí, con el parámetro mode en "w", y como parámetro obligatorio, el nombre de la referencia a la variable que almacena nuestra copia:

Ya tenemos todo lo necesario para poder escribir. Así que invocamos, ahora sí, al método write(). Debemos tener en cuenta que, al contrario de lo que sucede con la función print(), la función write() no incluye por defecto un salto de línea por lo que tendremos que incluirlo nosotros mismos.


Sólo nos resta cerrar el archivo con la consabida función close(). En el instante mágico, inextricable, inenarrable en que pulsemos enter, tendremos nuestra copia a nuestra entera disposición, en el caso del ejemplo, en el escritorio.


En la entrada T2.SERIALIZACIÓN: PONGA UN BINARIO EN SU DISCO DURO, veremos el concepto de serialización y como escribir y leer en binario (bytes).
En la entrada T2.WITH: EN BUENA COMPAÑÍA, veremos cómo funciona la declaración with y qué podemos esperar de ella.
Algunos de estos archivos externos pueden ser generados por el propio Python con el propósito de preservar los datos devueltos por la ejecución de un programa, vamos, que no se pierdan en el limbo de los justos cuando cerramos una sesión. ¡Voilà! Acabamos de descubrir el concepto de PERSISTENCIA DE DATOS o PERSISTENCIA DE LA INFORMACIÓN. Entendemos por PERSISTENCIA el proceso por el cual uno o más datos (información) obtenida como resultado de la ejecución de un programa, se conserva y es posible recuperar una vez hayamos cerrado la sesión, al cabo de un segundo, de una hora , de un día, de un año, de un siglo, de mil. Así la información quedará almacenada para ser re-utilizada por el mismo programa o por cualquier otro.

PYTHON DISPONE DE DOS MODOS DE ALMACENAR INFORMACIÓN PARA SU POSTERIOR REUTILIZACIÓN Y GARANTIZAR ASÍ SU PERSISTENCIA. POR UN LADO, A TRAVÉS DE LOS ARCHIVOS EXTERNOS QUE ACABAMOS DE MENCIONAR Y DONDE LOS DATOS OBTENIDOS NO PUEDEN RECUPERARSE PARA OPERAR CON ELLOS EN LOS PROGRAMAS Y, POR OTRO, A TRAVÉS DE BASES DE DATOS, BBDD, QUE SÍ PERMITEN SU REUTILIZACIÓN EN NUESTROS PROGRAMAS.
UNA SALCHICHITA DE POLLO... ¿NO?
Veámoslo en este esquema:

En el esquema hemos optado por poner de ejemplo un archivo *.txt de texto plano porque es el más sencillo y básico de construir y manipular. Vamos con ello.
Veamos cuál es el procedimiento para insertar datos en un archivo externo:
CREACIÓN → APERTURA→ MANIPULACIÓN DEL ARCHIVO → CIERRE
- CREACIÓN → APERTURA: Ambas acciones pueden darse a la vez.
- MANIPULACIÓN DEL ARCHIVO: Mostrar, extraer, agregar, modificar datos, copiarlos, etc.
- CIERRE: Siempre debemos cerrar el fichero en memoria al terminar la sesión.
Existen dos maneras aunque, realmente, en última instancia viene a ser la misma: todo se basa en la función open(). Ahora bien, podemos llamarla desde la librería estándar donde Python la guarda bien calentita, usando una importación parcial o relativa, del modo siguiente: from io import open. O bien podemos hacerlo directamente invocándola como una función preconstruida: open(). En ambos casos el resultado es el mismo. Su uso nos permite manejar el stream, la retransmisión de datos desde un data búfer, para facilitar flujos de datos bidireccionales desde el propio programa hacia el exterior y viceversa (leemos datos almacenados, escribimos más datos, volvemos a leer los datos originales más los que acabamos de añadir, volvemos a escribir, volvemos a leer; sobreescrituras dinámicas, etc.).

La mayoría de los argumentos opcionales que podemos manipular en la función los podemos dejar así, tal cual están, con sus valores predefinidos. Los que realmente nos interesan, para su uso más básico y habitual, son, evidentemente, el primero, file, donde pasamos una string, una cadena de texto, con la ruta (path) y el nombre del fichero y su extensión correspondiente, normalmente, .txt, para trabajar con textos planos; mode, que especifica el modo de apertura del fichero, esto es, lo que queremos hacer con él; y encoding, al que deberíamos dar siempre el valor "utf-8" si no queremos pasar dolores de cabeza y jaquecas varias.
Sobre este último asunto, observemos el siguiente ejemplo:

Vemos como, por defecto, Python tiene un sistema propio de codificación de archivos, de encoding, que es cp1252. Pues, posiblemente, con esta codificación por defecto vamos a ver lo mismo que un ciego con gafas de sol a medianoche, en mitad del campo y con luna nueva. Mejor le cambiamos la codificación a "utf-8", como se muestra al final del ejemplo y respiramos tranquilos.
Con el argumento file, pueden pasar dos cosas: una, que si el fichero no existe se cree al instante como por arte de magia; dos, si el fichero ya ha sido creado previamente, podamos abrirlo y ver su contenido, añadir cosas, reescribir, etc. En ambos casos, el fichero se creará en la carpeta que pasemos como path o, lo localizaremos para manipularlo en la ruta donde esté almacenado.
¡CUIDADO! EN WINDOWS, PYTHON NO LEE LAS RUTAS (PATHS) CON LA SINTAXIS PROPIA DEL SISTEMA OPERATIVO, SINO QUE TIENE SU PROPIA FORMA DE HACERLO. AFORTUNADAMENTE, SÓLO AFECTA A LA DIRECCIÓN DE LAS BARRAS DELIMITADORAS. MIRAD ABAJO:


Para crear un fichero que, por cierto, de no existir previamente, es lo primero que tenemos que hacer para poder realizar el resto de operaciones (somos programadores, no magos), podemos declarar una variable que almacene el resultado de la lectura de la función open(). Como primer argumento, obligatorio, de la función, pasamos como cadena de texto, es decir, entre comillas, un nombre de archivo, el que queramos, el que más nos guste, con su correspondiente extensión .txt. Como segundo argumento debemos indicar el modo (mode) en que queremos abrir el archivo y que, también, debemos pasar como cadena de texto. Recordemos que de modo predeterminado, el modo de la función es de lectura, "r", por lo que tendremos que modificar el valor de la propiedad, bien a "w", para crear/escribir nuestro archivo como tal; o bien "wb", si vamos a crear/escribir un archivo en codificación binaria. Por cierto, no es necesario escribir la propiedad (mode="w"): nos basta con escribir el valor a secas.
Vemos un ejemplo:

Podemos observar en la sección superior, que se corresponde con la codificación Python en el IDLE, que hemos llamado a una importación parcial de la función open() desde el módulo io de la librería estándar de Python aunque, como ya hemos dicho y volvemos a recordar aquí, podemos acceder directamente a la función open() sin necesidad de importaciones, por cortesía del intérprete.
A continuación, declaramos una variable, textfile, a la que asignamos la función open() y a la que pasamos dos argumentos: el nombre de archivo que queremos con su correspondiente extensión .txt, "file.txt", y el modo "w" (fijémonos que hemos prescindido de incluir el nombre de la propiedad) para crear el archivo.
Con lo que acabamos de hacer, ya tenemos un archivo de texto en blanco preparado para insertar en él todo el texto que queramos.
¿Y cómo lo hacemos?
Muy fácil. Podemos declarar una variable, dato, en el ejemplo, y asignarle, obviamente como string, el texto que queramos. A continuación llamamos a la variable que almacena la función, textfile, y por la sintaxis del punto, le pasamos el método write() que, como su nombre indica (to write=escribir), nos permitirá escribir aquéllo que le pasemos como argumento sobre nuestro archivo recién creado, blanco e inmaculado. Si queremos, podemos pasarle directamente una string, quizás más cómodo según para qué, pero también menos plástico.
Observemos que se nos devuelve un número: 47, en el ejemplo. ¡Anda! ¿Y ésto? Obedece a que la ejecución de la función devuelve por defecto el número de caracteres de la cadena, esto es, su tamaño, como podemos confirmar si le aplicamos la función len().

* IMPORTANTE: Siempre que creemos o abramos un fichero, cuando hayamos terminado de operar con él, debemos cerrar sesión mediante el método close() que aplicamos a la variable que almacena a la función mediante la sintaxis de punto. Por lo pronto, nos permite liberar recursos de nuestro pc, sobre todo, memoria caché. Pero lo más importante es que consigue que la información que vamos introduciendo en el fichero, de facto, virtual, sólo en el momento de cierre, se "formaliza", se imprime y se nos hace visible, negro sobre blanco, en nuestro fichero, como podemos comprobar en la sección inferior del ejemplo. Aquí, en el encabezado, podemos ver que lo hemos abierto en el bloc de notas de Windows así como el nombre, "file", que le dimos en el momento de su creación. La impresión en un fichero abierto en modo "w", por defecto, se realiza siempre desde la esquina superior izquierda del lienzo, que se corresponde con la posición inicial del prompt de escritura (la barrita vertical parpadeante). Como cuando construimos nuestro texto usamos una expresión regular para el salto de línea, \n, entre medio y que ya hemos empleado en otras ocasiones, en el archivo de texto se nos muestra dos líneas de texto.

TENGAMOS SIEMPRE EN CUENTA QUE CADA VEZ QUE USAMOS EL MODO "w" DE ESCRITURA PARA CREAR UN ARCHIVO, SI ÉSTE YA EXISTE (EL NOMBRE QUE LE PASAMOS COMO PRIMER ARGUMENTO DE LA FUNCIÓN YA EXISTE EN EL DIRECTORIO EN EL QUE ESTAMOS TRABAJANDO CON LA MISMA EXTENSIÓN .txt), PYTHON SITUARÁ EL PROMPT DE ESCRITURA DE NUEVO EN EL ÁNGULO SUPERIOR IZQUIERDO Y SOBREESCRIBIRÁ TODA LA INFORMACIÓN QUE HAYAMOS ESCRITO PREVIAMENTE EN EL ARCHIVO, SUSTITUYÉNDOLA POR LA NUEVA. ¡NO DIGÁIS QUE NO OS LO HE ADVERTIDO!
 |
| VIVIENDA TÍPICA DE ARICO EL NUEVO, EN LAS MEDIANÍAS DEL SUR DE TENERIFE. |

Observemos que hemos pasado una ruta, un path, como primer argumento de la función, con el nombre de archivo y su extensión al final. Esto lo hacemos para conseguir que nuestro fichero se almacene en una carpeta o directorio de nuestra elección, y no necesariamente en la carpeta del programa (podemos localizarlo arriba, a la izquierda, sobre el fondo negro del salvapantallas). También hemos optado por introducir directamente el texto como argumento de write(). Pero lo que realmente importa es que hemos introducido en la zona de argumentos de open() la propiedad encoding="utf-8". En la sección inferior vemos el resultado.
Vemos otro ejemplo similar:
Para evitar un borrado incidental de un fichero de texto previamente creado, Python nos provee del modo "x" que usaremos en lugar de "w". ¿Qué ocurre si usamos "x" en lugar de "w"? Que en el flujo de lectura, si el intérprete de Python encuentra que el nombre de fichero que le hemos pasado a la función open() ya existe, detiene automáticamente la ejecución y lanza una excepción de tipo FileExistsError como un castillo. Recordemos que podemos gestionar las excepciones para obtener las lecturas adecuadas a nuestros intereses como programadores (v. TRATAMIENTO DE EXCEPCIONES). En consecuencia, "x" aborda la creación exclusiva de un fichero, por lo demás, con un comportamiento similar al de "w".


Aún nos queda por ver dos modos más de escritura:
El modo "a" permite la apertura de un fichero de texto preexistente en modo add (to add=añadir). Como su nombre indica, nos permite adicionar, agregar, añadir más texto a un contenido ya existente. Y lo hace porque, contrariamente al comportamiento de "w", que sitúa el cursor siempre al comienzo del lienzo provocando el borrado de todo el texto preexistente (sobreescritura, recordemos) , el modo "a" lo sitúa justo a continuación del último carácter del texto, permitiéndonos añadir texto a partir de aquí, pero no hace un salto de línea. Por este motivo, si queremos añadir más texto al mismo párrafo, debemos dejar un espacio en blanco para que los caracteres no se junten, que queda feo; y si por el contrario queremos iniciar un párrafo nuevo, aparte, comenzar con un salto de línea, "\n", para asegurarnos que el párrafo se muestre en un bloque distinto al anterior.
Tengamos en cuenta que el carácter escape "\n" se puede colocar al principio de una cadena para escribir debajo de ésta, y/o al final, para que cualquier texto posterior se escriba debajo, en una nueva línea.
Sin embargo, con estas cosas nuestro Python se vuelve un poquito quisquilloso: lo que acabamos de decir es válido si pasamos el texto directamente como argumento de la función write(), porque si asignamos el texto a una variable y, luego, pasamos ésta como argumento de la función write(), el intérprete de Python no lo va a tener en cuenta.
PODEMOS ESTABLECER SALTOS DE LÍNEA MÁS AMPLIOS QUE EL TAMAÑO DE UNA SIMPLE LÍNEA CON ALGORITMOS COMO ("\n" * 5), QUE INTERPONDRÁ 5 LÍNEAS ENTRE EL FINAL DE UN PÁRRAFO Y EL COMIENZO DEL OTRO.
Vamos a verlo en los ejemplos siguientes.


Finalizamos los modos de escritura con el híbrido "r+" que permite al mismo tiempo leer y escribir de cara a actualizar un fichero: "r+" ⟶ Actualización. La apertura de un fichero en este modo nos permite leerlo y, a la vez, escribir datos en él. Se realiza una sobreescritura en lugar de una simple inserción de texto. Además, sitúa el cursor de escritura justo a continuación del último carácter que hayamos escrito de modo que, si estamos al final del fichero, se comporta de modo análogo a "a". Veámoslo:

 |
| COSTA ABRUPTA Y REBUFO DE OLAS EN LA COSTA DE DE LAS ERAS, MUNICIPIO DE FASNIA, SUR DE TENERIFE. |
VISTAZO PREVIO AL MÉTODO seek():
Vamos a imaginarnos que tenemos el siguiente texto creado con el modo "w" de escritura de ficheros:

Ahora que lo hemos creado, lo volvemos a abrir en modo "r" de lectura y pedimos que nos imprima el resultado en pantalla. Abrimos también el documento filename.txt. Percatémonos de que el puntero del prompt parpadea al inicio del texto en base a un comportamiento predeterminado en Python:

Con el prompt en esta posición, si nos decidiéramos a escribir un nuevo verso latino en nuestro flamante fichero, el texto comenzaría a escribirse a partir de aquí. Si quisiéramos escribir Nunc obdurat et tunc curat, nos ocurriría esto:

Sin embargo Python, una vez más, acude en nuestra ayuda y nos proporciona la opción de ignorar este comportamiento por defecto, y desplazar la posición del puntero hacia cualquier posición a partir de la cual deseemos escribir, lo que nos permite la intersección o interpolación de texto entre cadenas.
Nuestro héroe es el método seek() (to seek=buscar). Este método sólo lleva un argumento: un número entero que apunta el carácter del texto ya escrito a partir del cual debe situarse el prompt de escritura de tal modo que, si quisiéramos repetir el texto, nos basta con pasar el valor 0 y volver a repetir la instrucción de impresión ya que, después de la primera impresión, con seek(0), el puntero se resitúa al principio repitiendo todo el proceso.

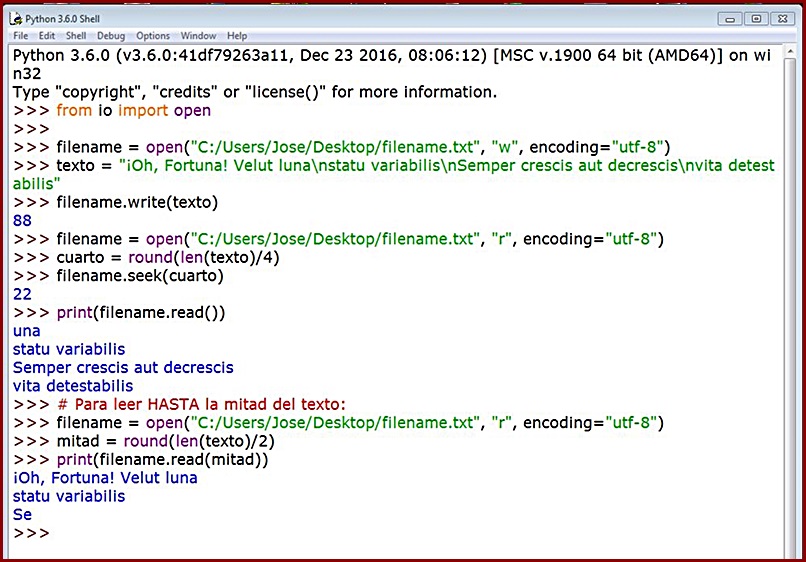
Si pasamos como argumento un entero distinto, el prompt se ubicará en la posición seleccionada, y será a partir de aquí desde donde podremos empezar a insertar texto. Si, como ocurre en el ejemplo, lo tenemos en modo "r" de lectura, no tendrá en cuenta los n primeros caracteres en la impresión, y comenzará a leer a partir de n, siendo n el número entero que pasamos como argumento de seek():

La propia función read() tiene un comportamiento análogo a seek() en cuanto al reposicionamiento del prompt, aunque diametralmente opuestos. Veámoslo con un ejemplo:
- seek(15) ➜ Python comienza a leer desde aquí en adelante.
- read(15) ➜ Python comienza a leer desde el principio hasta el carácter número 15 del texto.


Nos podemos apoyar en nuestra función amiga len() si se nos antoja colocar el prompt en una posición determinada del texto, bien fuera la mitad, un cuarto o un tercio del mismo. Veamos un ejemplo a continuación que nos permite leer a partir de la cuarta parte de un texto dado:
También podemos usar seek() para leer a partir de una línea determinada, para lo que deberíamos utilizar la función readlines(). Así que para saber de qué va esto de seek() comencemos por saber de qué va readlines(). O, aún mejor, readline(), ¡ojo!, 🙋, sin 's' al final.

LECTURA DE LÍNEAS DE TEXTO:
La función readline() nos permite, precisamente, leer línea por línea de texto del archivo por cada salto de línea: \n. Con ella obtendríamos la primera línea de texto en un orden lógico. Veamos:

Con la aplicación de la función sobre el texto anterior, obtenemos:


Contamos con la opción de recurrir a un bucle for/in y considerar nuestro archivo de texto como un iterable, de manera que el método lo recorra como una secuencia, devolviendo como resultado un texto mejor estructurado para su lectura.

Así da gusto, ¿Verdad? 👏
Cuando llegamos al final de un texto, devolverá una cadena vacía.
Teniendo esto en cuenta, podemos igualmente recurrir a un loop while con un resultado similar al que conseguimos con el bucle for/in:

Recordemos cerrar siempre los archivos abiertos con el método close() que, recordemos, cierra un archivo previamente abierto (aunque parezca de perogrullo, esto hay que dejarlo claro). Si tuviésemos un archivo para escritura abierto, desecharía cualquier otro texto que no hubiéramos guardado previamente. Lo vemos con un ejemplo aplicado aprovechando un ejemplo de readline().

 |
| LAURISILVA. PÍJARAS (HELECHOS woodwardia radicans) CRECIENDO SOBRE UN MANTO DE MUSGO EN UN TRONCO DE LAUREL. ROQUE NEGRO. MACIZO DE ANAGA. |
LA FUNCIÓN readlines():
Esta función, esta vez sí, con "s" al final, nos permite leer un texto dado línea por línea por cada salto de línea: \n.
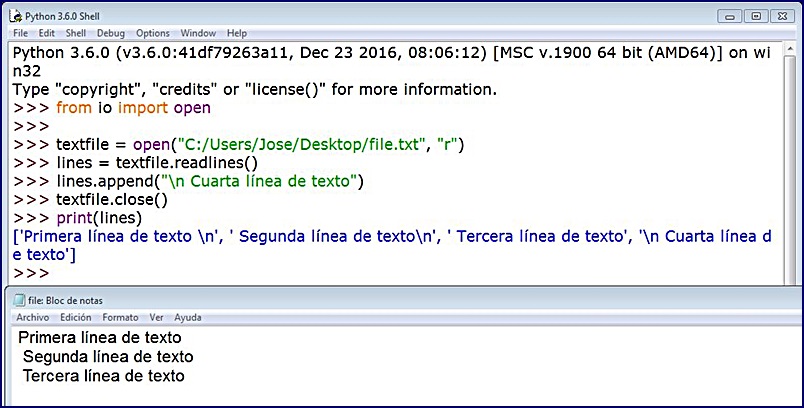
La información que nos devuelve se guarda en una secuencia de tipo lista, list, donde cada elemento representa una línea acotada por su correspondiente salto de línea, lo que subsecuentemente nos facilita generar código de búsqueda y localización para la posterior manipulación de datos. Lo entenderemos mejor con un ejemplo donde, además, comparamos ambos métodos readline() y readlines():

Las listas, como secuencias iterables que son, nos permiten buscar elementos concretos mediante el uso de filtros y de condicionales if o, directamente, iterar sobre sus ítems con el bucle for/in.
Comprobamos en el ejemplo que mostramos a continuación que el hecho de, por ejemplo, añadir un nuevo ítem a la lista mediante el método list.append(x), no implica necesariamente que se añada la nueva información al fichero de texto original:
LECTURA DE UN NÚMERO DADO DE CARACTERES:
Hablamos de un procedimiento que nos permite controlar el uso de memoria en el momento de leer un fichero de texto, y mostrar sólo una cantidad de texto específico según el número de caracteres total, o el espacio que dispongamos en nuestro programa para mostrar texto. Esto equivale a un "paquete" de memoria concreto. Para conseguirlo pasamos el número de bytes que consideremos oportuno como argumento de la función read().

En el ejemplo vemos que las devoluciones son cadenas de texto, string, con un tamaño o longitud (len()) acorde al argumento. Como vemos en 1., son sumativas, es decir, si pedimos un primer tamaño de x caracteres, al momento de pedir una segunda cadena con un tamaño especificado de n caracteres, éste comienza a contar a partir de x. Cuando no hayan más caracteres que mostrar, como en 2., se mostrarán cadenas vacías.
MÉTODOS seek() Y tell():
Los métodos seek() y tell() nos permiten recorrer un fichero de texto bajo algunas limitaciones. El método seek() que ya presentamos en sociedad un poco más arriba, lleva dos parámetros, ambos de tipo numérico entero. El primero atiende al desplazamiento y el segundo, al punto de partida. Su sintaxis es la siguiente: fichero.seek(desplazamiento, punto de partida).
El parámetro desplazamiento pueden ser un entero positivo. En caso de que el valor de punto de partida fuera 1 ó 2, el valor del desplazamiento es negativo. El parámetro punto de partida es de carácter opcional y puede tomar los valores siguientes:
El parámetro desplazamiento pueden ser un entero positivo. En caso de que el valor de punto de partida fuera 1 ó 2, el valor del desplazamiento es negativo. El parámetro punto de partida es de carácter opcional y puede tomar los valores siguientes:
- 0: Es el valor de desplazamiento por defecto si no se pasa valor alguno. Tengamos en cuenta que el desplazamiento comienza desde el inicio mismo del fichero.
- 1: El desplazamiento comienza a partir de la posición actual del fichero.
- 2: El desplazamiento comienza desde el final del fichero.
Los valores asumibles por el parámetro punto de partida, por su parte, dependen del resultado de la ejecución de la función asociada tell(), que nos devuelve la posición de lectura/escritura del fichero en cuestión. El tipo de dato que devuelve, bien puede ser un entero, si el fichero se abre en modo texto; o bytes, si se abre en modo binario. En cualquiera de los dos casos se nos remite a una posición específica dentro del fichero, posición que no es estrictamente asimilable a una secuencia de caracteres prototipo, lo que abunda en un cierto grado de arbitrariedad que afecta a la función seek(), que sólo permite ejecutar desplazamientos relativos al inicio del fichero de texto, y con un comportamiento similar a cómo se disponen los ítems en un diccionario, si antes no se filtra por la función tell() cuya devolución determina los valores que puede asumir seek().
 |
| MAGARZAS (MARGARITAS ENDÉMICAS EN CANARIAS) BICOLORES POR LAS CUMBRES DE ERJOS, PASO ENTRE EL NORTE Y EL OESTE DE TENERIFE, BORDEANDO EL MACIZO DE TENO. |
MÉTODO ALTERNATIVO DESDE EL PAQUETE Tkinter DE APERTURA DE FICHEROS:
Aunque apenas se usa, sobre todo, en las versiones modernas del lenguaje, no está de más contar con una alternativa más a la función integrada open() y a la dependiente de la librería estándar io, que hemos visto hasta ahora. Resulta un proceso más engorroso pero, al fin y a la postre, igualmente efectivo. Veámoslo.
Lo primero que tenemos que hacer, como ya habremos adivinado, es invocar en nuestro IDLE a un paquete (package) nativo de Python directamente vinculado con la interfaz gráfica de usuario, llamado Tkinter. Lo haremos con la sintaxis de importación que queramos aunque, como sólo vamos a solicitar un módulo único, es preferible optar por una importación parcial, como veremos en el ejemplo. Este módulo se llama filedialog y, una vez dentro del mismo, invocamos al método askopenfilename(), ¡vaya nombrecitos! que tiene la consideración y amable costumbre de preguntarle (to ask) a nuestro disco duro por tal o cual archivo que queramos abrir, devolviéndonos la ruta (path) para acceder a él.


Una vez que lo hemos hecho, pulsamos enter y se nos abre el siguiente display en la pantalla de nuestro pc:

1. Es una ventana (ventana gráfica) que se abre por defecto cada vez que trabajamos con Tkinter como paquete destinado al desarrollo GUI (Graphic User Interface), donde veríamos el resultado de nuestros códigos siempre y cuando estuviéramos trabajando con Tkinter en modo gráfico. Como este no es el caso, podemos eliminarla clicando sobre la x, en el extremo superior derecho, minimizarla o arrastrarla fuera de nuestro área de trabajo.
2. Ventana informativa de carpetas y directorios de Python que se corresponde con la ventana actual del sistema, y que nos permite apuntar a cualquier archivo que tengamos almacenado en ella. Por defecto, muestra la carpeta matriz de sistema (Python34, en el ejemplo. Lo podemos ver en el campo de texto: Buscar en:, en la parte superior. Muestra la carpeta de la versión actual de Python en la que estemos trabajando), donde podremos llamar al archivo que queramos. En nuestro caso, en el ejemplo, iremos al escritorio (accederemos a él, de manera sencilla, pulsando sobre el icono correspondiente, a la izquierda de la ventana), donde ya tenemos preparado un archivo de texto sobre el que trabajar.
3. La ventana del IDLE, con el código que hemos introducido hasta el momento, a la espera de continuar.

Seleccionamos el fichero que nos interesa.

Y hacemos doble clic sobre él para que, automáticamente, se muestre su ruta de acceso (path) en el shell.

Sólo hemos mantenido la ventanita del Tkinter para comprobar que podemos arrastrarla y colocarla donde queramos sin que desempeñe papel alguno en el proceso de apertura de un fichero de texto. Como nos es del todo irrelevante, la eliminaremos sin más.
Para clarificar mejor el proceso, volvemos al principio de nuestro código y, tras las importaciones, guardamos en una variable la ruta (path) que nos proporciona el método askopenfilename(), tal cual vemos a continuación:

Comprobaremos que, en efecto, nuestra variable path contiene la ruta devuelta por el método:

Seguidamente, declaramos una segunda variable donde almacenaremos el resultado de la aplicación de un método nuevo de filedialog que llamaremos a continuación: asksaveasfilename(), que guarda (to save) como un nombre de archivo (as filename) una copia del archivo que hemos seleccionado, DDHHART.txt:

Cuando pulsamos enter se nos volverán a abrir las ventanitas de marras pero, en esta ocasión, en la ventana de directorios. En la parte inferior, en el campo de texto correspondiente a NOMBRE:, escribiremos aquél que queramos darle a nuestra copia del archivo:


AUNQUE NO ES NECESARIO, SÍ ES CONVENIENTE AÑADIR LA EXTENSIÓN DE ARCHIVO CORRESPONDIENTE, EN NUESTRO CASO, .txt. PARA NUESTRO EJEMPLO, HEMOS SELECCIONADO EL NOMBRE DE ARCHIVO COPIA_DDHHART.txt.
Hacemos la prueba y, efectivamente, tenemos la copia guardada en su variable.
Ya tenemos los dos archivos: el original, DDHHART.txt, y su copia, COPIA_DDHHART.txt.
Vamos a proceder, pues, a su lectura. Para hacerlo primero tenemos que abrirlo con la función nativa que ya conocemos sobradamente: open(), y que almacenaremos en una variable que declararemos ad hoc. Sobre ésta, aplicaremos correlativamente el método de lectura, read() y, después, el de cierre, close(). Recordemos una vez más que constituye una buena práctica instruir la función de cierre de archivo para evitar sobrecargas innecesarias en la memoria del programa.

Ahora, toca abrir el archivo en el que vamos a escribir, de nuevo, claro está, con la función open() pero, eso sí, con el parámetro mode en "w", y como parámetro obligatorio, el nombre de la referencia a la variable que almacena nuestra copia:

Ya tenemos todo lo necesario para poder escribir. Así que invocamos, ahora sí, al método write(). Debemos tener en cuenta que, al contrario de lo que sucede con la función print(), la función write() no incluye por defecto un salto de línea por lo que tendremos que incluirlo nosotros mismos.


Sólo nos resta cerrar el archivo con la consabida función close(). En el instante mágico, inextricable, inenarrable en que pulsemos enter, tendremos nuestra copia a nuestra entera disposición, en el caso del ejemplo, en el escritorio.



En la entrada T2.SERIALIZACIÓN: PONGA UN BINARIO EN SU DISCO DURO, veremos el concepto de serialización y como escribir y leer en binario (bytes).
En la entrada T2.WITH: EN BUENA COMPAÑÍA, veremos cómo funciona la declaración with y qué podemos esperar de ella.
 |
| CAIDEROS DE AGUA EN EL CAUCE DEL BARRANCO DE LERE, ARICO, SUR DE TENERIFE. |
Una explicación muy completa y magistral, genial, gracias.
ResponderEliminarMuchísimas gracias, Uber Regé. Un placer enorme haber servido de ayuda. Te recomiendo que hagas clic en HERRAMIENTAS Y UTILIDADES, sobre la imagen del libro, en la parte superior del blog, para que puedas encontrar ahí, entre las diferentes opciones que se ofrecen, material nuevo de otros blogs, publicaciones y videotutoriales que te permitan profundizar más en éste aspecto y en otros de tu interés. Saludos.
ResponderEliminarGracias......No soy un programador EXPERTO, y por iniciativa estoy comenzando con este lenguaje.
ResponderEliminarTotalmente de acuerdo con lo que escribe el señor: Uber Regé.....
Se agradece compartir los conocimientos...
Muchas gracias, PIPE. Es un placer compartir conocimientos y avanzar juntos en el conocimiento de este lenguaje de programación. Te felicito por tu iniciativa: has hecho una excelente elección. Pronto comprobarás como tus competencias en programación mejorarán mucho. Saludos y ánimo con sus estudios.
ResponderEliminarGauber. Muchas Gracias muy buena la pedagogía. Excelente!
ResponderEliminarGracias a usted. Esperamos haberle servido de ayuda y que este blog esté siempre ahí para cuando lo necesite. Un placer. Saludos.
EliminarGracias Gauber. Sigo estudiando.
ResponderEliminar¿ Los f-string , format string aplican para write()?
ResponderEliminarHola. En principio sí que debería, tanto a la hora de escribir un texto por primera vez, cuando se usa el parámetro "w" como cuando se añade texto nuevo a otro ya escrito, en este caso con el parámetro "a", eso sí, siempre y cuando NO estemos escribiendo binarios. Puede verlo haciendo aquí:
Eliminarfrom io import open
programa = "Python"; version = "3.8.5"
texto = f'Estoy utilizando la versión {version} de {programa}'
print("Texto a imprimir: ", texto)
print()
file = open("C:/Users/USUARIO PRINCIPAL/Desktop/prueba.txt", "w", encoding="utf-8")
file.write(texto)
file.close()
Prefiero utilizar las cadenas f sobre la función 'format' porque es lo que recomienda el código de estilos de Python, pero si recurre a 'format' en su lugar, el resultado debe ser el mismo.
Efectivamente, nuestra cadena f es correcta: Texto a imprimir: Estoy utilizando la versión 3.8.5 de Python, y en el ejemplo, se genera en mi escritorio (desktop) de acuerdo a la ruta (path) que elegí como primer argumento de la función open(), un archivo de tipo .txt con el nombre 'prueba' que contiene exactamente el mismo texto.
Esperamos haber servido de ayuda. Saludos.