 |
| CASERÍO RURAL EN LOS ALTOS DE ARONA, SUR DE TENERIFE |
Vamos a dejar por ahora a los números un poco de lado y vamos a acercarnos, primero de rondilla y luego con mayor detalle a las CADENAS DE TEXTO o LITERARIAS, llamadas STRING, y que en Python pueden llamarse a través de la función string().
Veamos un ejenplo sencillo:
 |
¡Ya está! ¡Ya tenemos nuestro primer texto!
Lo primero que debemos observar es que hemos introducido una función nueva: print(). Esta función, "IMPRIMIR" en castellano, muestra en pantalla un resultado. Siendo aún más exactos, su única labor consiste en mostrar al usuario haciéndolo visible en el SHELL del IDLE de Python el resultado de ejecutar un código.
Desde el punto de vista del intérprete de Python es una función, válganos la paradoja, que no funciona, una función "inerte" por así decirlo que no hace otra cosa que, como ya hemos dicho, mostrar un resultado en pantalla. Por eso podemos decir que la función print() no es operativa desde la perspectiva del lenguaje: no trabaja sobre el código sino que nos enseña un resultado como consecuencia de la ejecución del mismo.
Como ya hemos comentado, y ese color magenta delata, print(), es una función, de la misma manera que todo lo que entrecomillemos se mostrará en verde. Así podremos distinguir rápidamente y de un solo vistazo en cualquier programa que desarrollemos en IDLE de Python cualquier string que se nos ponga por delante: siempre se mostrarán en verde. Y como toda función, lleva un paréntesis donde incluir una argumento. Pues bien: aquéllo que incluyamos entre los paréntesis será lo que se imprima en pantalla.
En nuestro ejemplo hemos insertado como argumento de la función un TEXTO, "BUENOS DÍAS" que, y he aquí la clave del asunto, el meollo de la cuestión, hemos puesto entre comillas.
En Python, los textos (string) deben escribirse entrecomillados, bien entre comillas simples (single quotes), esto es, ', o bien entre comillas dobles (double quotes), esto es, ". Aplicado a nuestro ejemplo, podemos escribirlo así: "BUENOS DÍAS", que es la manera más común de entrecomillar entre los países latinos; o bien así, 'BUENOS DÍAS', que es la forma más habitual de hacerlo en los países de habla anglosajona y germánica, por lo que lo veremos así escrito con más asiduidad cuando consultemos programas Python procedentes de USA o de otros países de la Commonwealth.
¿Y por qué se entrecomillan? Pues básicamente para facilitarle al intérprete la distinción entre nombres de variables y un simple texto mondo y lirondo. Recordemos que con un número esto no es necesario porque Python nos impide utilizarlos como identificador de una variable.
Si al cabo de haber creado una función print() pulsamos ENTER se nos mostrará en pantalla y en azul el argumento que lleva entre paréntesis.
 |
 |
Como podemos observar, el IDLE de Python, en su loable afán didáctico, nos advierte también de los errores que cometemos, en rojo, de acuerdo a la codificación por colores que integra por defecto. En este caso nos avisa de que se trata de un error de tipo sintáctico (SyntaxError). A continuación de los dos puntos nos señala por qué: no podemos asignarle un dato a una string (literal) de acuerdo a las restricciones para señalar un identificador para las variables que ya aprendimos del capítulo anterior...¿Que tal si hacemos un alto y aprovechamos para repasarlas?
Pongamos de nuevo el foco sobre la función print(). Seguro que si hemos probado a hacerlo nosotros en el SHELL, en el momento de escribir el paréntesis de apertura, igual que nos sucedía con type(), se nos muestra un cuadro de información:
 |
¿A que pone los pelos de punta, verdad? Sin embargo, es más sencillo de lo que parece. Se trata de tres argumentos de palabra-clave, (keyword, en inglés), a saber: SEP, END y FILE. Ya iremos viendo qué significa todo esto. De momento, quedémonos en que todo esto es lo que la función print() admite como argumento. Además, todas cuentan con valores por defecto (default), tal y como podemos observar en el cuadro de información: SEP -> un espacio en blanco; END -> \n, por el que se imprime una línea nueva, un salto de línea, al final de la llamada a print(); y FILE -> sys.stdout, que es la forma estandarizada en la que se muestran los archivos. Finalmente, FLUSH -> False, evita que se vacíe el buffer interno de Python cuando trabajamos con un archivo, reteniendo los resultados en la memoria caché, para acceder más rápidamente y mejor a la información. Fijémonos en que, al contrario que en type(), al final del paréntesis no aparece ninguna flecha, ->, lo que redunda en lo que ya hemos comentado sobre print(): una función que "no hace nada" operativamente hablando, que tan sólo muestra o devuelve en pantalla de un código o script.
 |
| PIÑA EN FORMACIÓN DEL PINO CANARIO (PINUS CANARIENSIS) |
Conviene dejar claro que ambas funciones, print() y type(), son funciones pensadas y creadas para facilitar el trabajo del programador. Carecen de operatividad alguna como herramientas de programación: si Python fuera un reloj y los programadores los relojeros, toda la sintaxis del lenguaje (objetos, funciones, datos, clases, herramientas de control de flujo, librerías, etc.) serían sus diferentes componentes (ruedecillas, engranajes, correas de transmisión, tornillería, etc.). En este supuesto, print() sería la lupa, el cristal sobre la esfera, que nos muestra la hora, y type() la etiqueta que podemos colgar sobre cada pieza para saber qué podemos hacer con ella.
Lo primero que nos dice, VALUE, es que podemos introducir un valor cualquiera, es decir, aquéllo que le asignamos a una variable, como por ejemplo, un dato numérico cualquiera:
 |
Los puntos suspensivos nos señalan que se pueden añadir más cosas, como la string del ejemplo, LISTAS, TUPLAS, DICCIONARIOS, etc. Sin embargo, print() no sólo es capaz de mostrar algo en pantalla. También le podemos indicar cómo queremos que nos lo muestre, sobre todo, cuando se trata de varios elementos. Es el caso, por ejemplo y como ya veremos en varias ocasiones a lo largo de este manual, cuando colocamos varias strings dentro de un mismo argumento, en cuyo caso debemos separar unas de otras mediante comas: si lo que queremos es una fila continua con un "separador" o "delimitador" entre los resultados ('SEP' es la abreviatura en inglés de "SEPARATOR") recurrimos a SEP="", al final de la lista y colocando entre las comillas el separador que queremos utilizar. Como separadores podemos utilizar cualquier carácter, desde un simple signo ortográfico, a un número u otra cadena de caracteres. Incluso espacios en blanco:
 |

Un detalle importante es que cada espacio que ocuparía una letra, un signo o un número, esto es, cualquier carácter literal es, precisamente eso, un carácter literal, por lo que un espacio vacío es también un carácter literal: si abrimos comillas y le damos a la barra de ESPACIO tres veces por ejemplo, y cerramos comillas, sin haber escrito nada, algo así como esto: " ", para Python contará como una secuencia de tres caracteres literarios. Constituye lo que se llama una STRING VACÍA. Tienes un ejemplo en la última línea de código del caso anterior, pero déjame mostrarte éste otro ejemplo para que lo veamos más claro:
 |
Por otra parte, también disponemos de la opción END=" " (olvidémonos del '\n' que se nos muestra en el cuadro de información) y que añade un carácter o un conjunto de caracteres al final de la serie de datos. Veamos un ejemplo:
 |
El resto de propiedades no nos interesan ahora mismo. De momento, con esto nos es suficiente.
También vamos a dejar de lado por el momento las muchas virtudes de la función más célebre, popular y querida de Python, la función print(). Regresaremos sobre ella más adelante y aprenderemos una cuantas cosas más.
De momento vamos a regresar a nuestras strings. Aunque pequemos de pesados, insistimos una vez más en que una string es todo aquello que pasamos entre comillas, simples o dobles. El número 48, tal y como está escrito, es un dato numérico del tipo INT. Pero si lo ponemos entre comillas, "48" o '48', se convierte en una string. Como tal ya ha perdido su condición de entero y, con ello, ciertas facultades operativas como, por ejemplo, ya no responde a los operadores aritméticos y, consecuentemente, no puede formar parte de un algoritmo o expresión matemática o aritmética. Sin embargo, como cadena literal ha ganado ciertas facultades operativas como, por ejemplo, el poder relacionarse con otras cadenas, operar con ellas mediante los OPERADORES DE STRING (de la misma manera que en Python contamos con varios OPERADORES ARITMÉTICOS para realizar operaciones con los números, como ya hemos visto, contamos también con varios OPERADORES DE STRING para hacer lo propio con las cadenas de texto) y aplicársele MÉTODOS DE STRING, que estudiaremos en profundidad en este mismo apartado.
Vamos a ilustrar todo esto con un ejemplo:
También vamos a dejar de lado por el momento las muchas virtudes de la función más célebre, popular y querida de Python, la función print(). Regresaremos sobre ella más adelante y aprenderemos una cuantas cosas más.
De momento vamos a regresar a nuestras strings. Aunque pequemos de pesados, insistimos una vez más en que una string es todo aquello que pasamos entre comillas, simples o dobles. El número 48, tal y como está escrito, es un dato numérico del tipo INT. Pero si lo ponemos entre comillas, "48" o '48', se convierte en una string. Como tal ya ha perdido su condición de entero y, con ello, ciertas facultades operativas como, por ejemplo, ya no responde a los operadores aritméticos y, consecuentemente, no puede formar parte de un algoritmo o expresión matemática o aritmética. Sin embargo, como cadena literal ha ganado ciertas facultades operativas como, por ejemplo, el poder relacionarse con otras cadenas, operar con ellas mediante los OPERADORES DE STRING (de la misma manera que en Python contamos con varios OPERADORES ARITMÉTICOS para realizar operaciones con los números, como ya hemos visto, contamos también con varios OPERADORES DE STRING para hacer lo propio con las cadenas de texto) y aplicársele MÉTODOS DE STRING, que estudiaremos en profundidad en este mismo apartado.
Vamos a ilustrar todo esto con un ejemplo:
 |
Aquí tenemos un ejemplo muy claro, ¿verdad? A la variable a le hemos aplicado un declaración de asignación mediante el operador = por el que le hemos asignado un valor o dato numérico, en este caso, el número 48. Con la aplicación de la función type() comprobamos que se trata de un entero (INT). Hacemos lo mismo con el valor de la variable b, 100 en este caso, que aplicando nuevamente la función type(), nos confirma que se trata de un entero como en el caso precedente. Como ambos son números podemos operar con ellos mediante los OPERADORES ARITMÉTICOS tal y como queda demostrado al solicitar una suma de a y b donde Python nos devuelve 148 como resultado. A continuación, y apoyándonos en el TIPADO DINÁMICO, podemos cambiar sobre la marcha el dato almacenado en una misma variable. En esta ocasión, tan sólo entrecomillamos el número 48. Al pasarlo como argumento de la función type() ésta ya nos advierte de que se trata de un dato o valor de tipo str, es decir, una STRING: Ya no es un entero, un INT. Cuando tratamos de repetir la misma operación aritmética, cuando tratamos de sumar de nuevo a y b, y observemos que no hemos modificado el valor original de b que sigue siendo un entero, al intérprete de Python le da un telele y nos lanza un error, en rojo (chillón), como la copa de un pino.

Las strings y los datos o valores numéricos, bien sean del tipo INT o, sobre todo, del tipo FLOAT no pueden realizar operaciones aritméticas entre sí. Existe una salvedad, una excepción muy concreta, con los enteros, que veremos próximamente dentro de las propiedades de las strings.
Traceback significa en Python "traza de rastreo", esto es, que Python ha efectuado un rastreo, una monitorización interna, un DEBUGGING, que así se llama en puridad el asunto, si lo entendemos mejor, del programa (por defecto lo hace en todos) en busca de 'BUGGS', errores o ausencias de codificación, fallos sintácticos y ortográficos, etc. a partir del momento, mágico, irrepetible, en que pulsamos la tecla ENTER. Y en cuanto encuentra una traza, un rastro, una pista, un "trace", de que se ha producido un error, nos lo señala de inmediato para amargarnos la existencia interrumpiendo, también por defecto, la ejecución del programa. Viene a ser, más técnicamente, un listado de todas las llamadas que se han realizado desde el punto donde se ha lanzado la excepción, donde ha acontecido el error, hasta el inicio de la "pila de llamadas". No nos preocupemos si no comprendemos ahora estos términos: son tecnicismos sin mayor importancia que veremos con la profundidad adecuada cuando estudiemos el capítulo dedicado a las EXCEPCIONES EN PYTHON.
El Traceback lo sitúa en (most recent call last):, esto es, en la última llamada que hemos hecho de nuestro módulo, realmente, en la ejecución que acabamos de realizar. Por eso, nos habla de un fichero, File "<pyshell#7>", que es un fichero que se crea "ad hoc" sobre la marcha, que a nosotros ni nos va ni nos viene ni falta que hace, y que se construye sólo para consumo de la máquina. Por cierto, el 7 apunta a todas las líneas de código que podemos encontrar antes de aquélla infausta que lanza el error. Si contamos los prompts que se encuentran por encima de >>> a + b contamos 7. Line 1, hace referencia a esa misma línea de código: como no tenemos ningún salto de línea en nuestra línea de código y, por consiguiente, es en una sóla donde reluce lindamente nuestro error, nos dice que es la línea 1. Como podemos imaginar, es lo más común que nos vamos a encontrar. Finaliza con in <module> que tan sólo nos informa que el error ha acontecido en el script o programa en el que estamos trabajando. Python lo entrecomilla, (< >), porque todavía no se trata realmente de un módulo. Todavía nosotros no lo hemos convertido en un MÓDULO, acción ésta fundamental que aprenderemos en su momento y que está en la base misma de la programación, aunque Python lo entiende como un "módulo en potencia" y de aquí el acotamiento.
A continuación Python nos avergüenza mostrándonos sin tapujos ni anestesia la causa del error: a + b, y remata la faena señalándonos el tipo de error producido entre todos los posibles (TypeError:): Vamos, que no podemos convertir un objeto entero, un número de tipo INT, en una cadena literal, es decir, en una string, str, implícitamente, porque sí, por nuestra cara bonita, porque nos dé nuestra realísima gana. Recordemos las restricciones de Python a la hora de operar entre enteros y cadenas literales.
De todas maneras, en Python es posible permutar números en clase string a números, tanto de tipo INT como FLOAT, y viceversa de una manera sencilla mediante el uso de la función y sintaxis type(object(dato)) como podemos ver a continuación:
El Traceback lo sitúa en (most recent call last):, esto es, en la última llamada que hemos hecho de nuestro módulo, realmente, en la ejecución que acabamos de realizar. Por eso, nos habla de un fichero, File "<pyshell#7>", que es un fichero que se crea "ad hoc" sobre la marcha, que a nosotros ni nos va ni nos viene ni falta que hace, y que se construye sólo para consumo de la máquina. Por cierto, el 7 apunta a todas las líneas de código que podemos encontrar antes de aquélla infausta que lanza el error. Si contamos los prompts que se encuentran por encima de >>> a + b contamos 7. Line 1, hace referencia a esa misma línea de código: como no tenemos ningún salto de línea en nuestra línea de código y, por consiguiente, es en una sóla donde reluce lindamente nuestro error, nos dice que es la línea 1. Como podemos imaginar, es lo más común que nos vamos a encontrar. Finaliza con in <module> que tan sólo nos informa que el error ha acontecido en el script o programa en el que estamos trabajando. Python lo entrecomilla, (< >), porque todavía no se trata realmente de un módulo. Todavía nosotros no lo hemos convertido en un MÓDULO, acción ésta fundamental que aprenderemos en su momento y que está en la base misma de la programación, aunque Python lo entiende como un "módulo en potencia" y de aquí el acotamiento.
A continuación Python nos avergüenza mostrándonos sin tapujos ni anestesia la causa del error: a + b, y remata la faena señalándonos el tipo de error producido entre todos los posibles (TypeError:): Vamos, que no podemos convertir un objeto entero, un número de tipo INT, en una cadena literal, es decir, en una string, str, implícitamente, porque sí, por nuestra cara bonita, porque nos dé nuestra realísima gana. Recordemos las restricciones de Python a la hora de operar entre enteros y cadenas literales.
De todas maneras, en Python es posible permutar números en clase string a números, tanto de tipo INT como FLOAT, y viceversa de una manera sencilla mediante el uso de la función y sintaxis type(object(dato)) como podemos ver a continuación:
 |
Sencillísimo, ¿verdad?
 |
| ALMACÉN O GRANERO EN UNA EDIFICACIÓN RURAL TÍPICA, EN BLOQUE DE JABLE O PUMITA Y ARGAMASA, EN LOS ALREDEDORES DEL ROQUE DE JAMA, EN EL SUR DE TENERIFE. |
Recapitulemos: una string o str es uno de los distintos tipos de dato que emplea Python y que representa cadenas, llamadas "literales" o de "texto", que constituyen a su vez, secuencias de caracteres Unicode. Cualquier carácter o secuencia de éstos (y aprovechamos para dejar constancia de que para la "mente" de Python un carácter se define como un carácter de longitud 1, valga la redundancia, sobre una línea de n caracteres de longitud: una colección de caracteres de 7 contiene siete caracteres, cada uno de ellos de longitud 1 ¿A que mola?) que pongamos entre comillas, como ya sabemos, ya sean dobles o simples, se convierte automáticamente en una string, variando en el SHELL su color a verde para mostrárnoslo de una manera más gráfica y fácil de identificar. Aquí podemos colocar letras, construyendo o no contenidos semánticos, es decir, que tengan un significado reconocido en un idioma humano cualquiera, en castellano, por ejemplo; dígitos; signos, como pueden ser, +, *, >, <, ^, ¿, $, %, @, etc.; y espacios en blanco, o caracteres en blanco, que también cuentan, y que empleamos para separar las palabras, poder leerlas correctamente y comprender su significado. Cada espacio en blanco, como podemos imaginar, ocupa exactamente el mismo espacio que ocupa un carácter literal, esto es, una longitud de 1, una única pulsación de BARRA ESPACIADORA para entendernos, vaya.
Veamos lo siguiente: "buenos días" tiene para Python 11 caracteres, de los cuales 10 son literales y uno es un espacio en blanco que separa ambas palabras y que cuenta también como carácter literal, todos estos de longitud 1. La suma de todos ellos, como ya hemos dicho, es de 11 caracteres.
Y esto lo podemos comprobar llamando o invocando a una nueva función nativa de Python, como lo son print() o type(): la función len() que nos dice la cantidad exacta de caracteres literales que componen una string. Procedamos a aplicarla a nuestro ejemplo:
La función len() es la contracción del término inglés 'length', "longitud", en castellano, que ya nos proporciona una idea de lo que hace esta función. Observemos que lo único que tenemos que pasar como argumento de la función es la propia string o, hagamos memoria, el nombre o identificador que referencia un espacio en la memoria que alberga un dato, en este caso, de tipo string. Sí, sí, que sí: la variable que contiene a la string.

Hagamos una precisión importante: cuando queramos introducir un texto previamente entrecomillado, como por ejemplo, una acotación o una cita, debemos tener en cuenta que no podemos repetir el tipo de comillas: si optamos por iniciar una string con comillas dobles ("double quotes"), en el momento que vayamos a introducir la cita debemos recurrir a las comillas simples ("single quotes") porque, de lo contrario, Python entenderá que la string termina aquí, continuar con el texto y, efectivamente, cerrar nuestra cadena tal cual como la hemos empezado: con comillas dobles.
Ilustremos el caso con un ejemplo:
Como vemos, podemos imprimir el texto sin problemas en pantalla alternando las comillas dobles y simples, nunca emparejando dos grupos de comillas dobles o dos grupos de comillas simples. Fijémonos cómo se suscita un error cuando no respetamos la restricción:
Durante el proceso mismo de escritura podemos percatarnos de que en el momento mismo en que colocamos la segunda comilla o comilla de cierre, nuestro texto abandona el colo verde característico de las strings y adopta el negro característico de los datos. ¡Uy! Algo va mal...
En la detección del error, Python nos subraya la palabra 'Leoncitos' (podemos hablar de substrings, partiendo de la base de que una substring puede entenderse como una porción de una string, habitualmente y de cara al programador humano, aquellas porciones que tengan un significado por sí mismas como, por ejemplo, una palabra, un subtexto, un título, etc., en nuestro ejemplo, 'Leoncitos', básicamente, porque cuando escribimos un texto pretendemos que se muestre en pantalla y que éste sea leído y comprendido por otro/s ser/es humanos, por lo que dicho texto está conformado a su vez por distintos elementos legibles y comprensibles para nosotros como sustantivos, pronombres, verbos, adjetivos, etc. que constituyen los 'ladrillos' con los que componemos los textos de nuestro idioma, igual y necesariamente legibles y comprensibles, y es precisamente en estos 'ladrillos', como lo es el sustantivo 'Leoncitos' con los que solemos trabajar cuando introducimos texto en nuestros códigos para construir correctamente esos mismos textos. Sin embargo, también son substrings en última instancia cualquier carácter literario que forme parte de otro mayor sea cual sea la longitud del primero siempre y cuando no supere la longitud (len()) menos 1 (al menos) de la string de la que forma parte: 'L' es una substring de 'Leoncitos'; 'onci', también; 'tos', también; 'Leoncito', también; pero 'Leoncitos' no porque no es la longitud de la string menos 1, sino que muestra una longitud similar a la de la string que lo contiene, luego es la propia string y no una substring propiamente dicha). Así el intérprete de Python nos señala dónde se encuentra el yerro y desde dónde empieza.
Por cierto, y enlazando con lo que comentábamos unos párrafos más arriba, aquí no se lanza ninguna excepción del tipo Traceback. No hay ningún "rastreo de error". ¿Por qué? Porque Python detecta el error justo cuando cerramos la línea de código que estamos escribiendo y pulsamos ENTER para escribir una nueva. Se trata casi siempre de errores ortográficos (¡ay, que no le pusimos la tilde a 'ortograficos', por ejemplo) que no demandan la ejecución de un programa, y errores de sintaxis (¡ay, que pusimos el artículo después del sustantivo en 'pelota la', por ejemplo), antes que errores gramaticales que sí suelen advertirse cuando se demanda la ejecución del mismo.
En resumidas cuentas, cuando vamos a introducir una acotación o una cita:
Veamos qué nos devuelve la función str() en función de los argumentos que le pasemos:
La función str() puede recibir dos argumentos opcionales que deben ser pasados como cadenas: uno especifica la codificación mientras que el otro determina cómo deben manejarse los errores de codificación. Esto no nos interesa de momento y lo mostramos aquí tan sólo a título informativo:
Un último dato para redondear este apartado: todas las strings en Python tienen formato Unicode, de manera similar a lo que sucede con la casi totalidad de los lenguajes de programación modernos. Si nos apetece tener, al menos, una idea básica de lo que significa esto, podemos consultar la siguiente entrada. La hemos etiquetado como T2 pues contiene algunos conceptos que no hemos tocado aún, pero por su sencillez y escasa complejidad, podemos leerla al cabo de este artículo si nos apetece.
T2. CODIFICACIONES DE CARÁCTER. LA UNIÓN HACE LA FUERZA.
Ver la siguiente entrada:
T1. OPERADORES DE LAS STRING. TAMBIÉN TIENEN DERECHO.
Obviamente, cuando escribimos una string (y, por extensión, cuando escribimos cualquier cosa en nuestro ordenador, ya sea un documento de texto, codificamos un programa, introduzcamos nuestros datos en un formulario en un sitio web, etc.), lo hacemos de manera habitual a través del teclado, ése gran desconocido que tanto nos da y tan poca importancia damos. Aquí encontramos la mayor parte de los caracteres literales de nuestro idioma, siempre y cuando estemos usando uno adaptado de forma específica al nuestro propio, por ejemplo, un teclado para hispanohablantes debe contener la 'ñ', mientras que para los que sólo usan el inglés, el carácter 'ñ' es inútil, y los dígitos, del 0 al 9, que necesitamos para expresarnos. Además, contiene una serie de signos y símbolos de uso común, como =, + , @, (, /, *, ·, etc. a los que podemos acceder, o bien directamente, pulsando la tecla correspondiente, o bien indirectamente, mediante una combinación de las mismas.
Como ya sabemos, por eso todos los lenguajes de programación habidos y por haber, para facilitarnos las cosas a nosotros, sufridos programadores, utilizan estos mismos signos, sólos o en combinación con otros, como operadores de todo tipo, cuantificadores, limitadores, etc por su universalidad y su fácil acceso.
Pero... ¿qué sucede con ciertos signos y símbolos que nos gustaría emplear en nuestros programas y no se encuentran entre nuestras opciones predeterminadas de teclado? ¿Qué pasa con el símbolo de la raíz cuadrada? ¿Y el de exponenciación al cuadrado? ¿Dónde diantre está la sigma mayúscula griega que apunta al sumatorio total matemático? Y ya que estamos, ¿Y si queremos usar caracteres del alfabeto griego, por ejemplo, para senos, cosenos, tangentes y otras lindezas trigonométricas?...
Veamos esta captura:

¿Cómo hemos conseguido que se muestren esos signos de exponenciación y raíz en la calculadora del ejemplo?
Pues haciendo uso de los caracteres ASCII correspondientes.
¡Ah!... ¿Y cómo podemos implementarlos en nuestro código para que, por ejemplo, se muestren en pantalla cuando ejecutemos un print()?
Llamándolos mediante una sintaxis propia que responde al siguiente formato: "\uxxxx", donde a partir de \u cada x, hasta un máximo de cuatro, se corresponde con una secuencia alfanumérica que, en la mayor parte de los casos, comienza en 2. También es posible encontrar otra modalidad, "\xxx", que apunta a ciertos símbolos y caracteres especiales ASCII. Es posible hallar algún otro formato sintáctico más, según lo que vayamos buscando, pero la mayoría de los más usuales se atienen a la sintaxis que mostramos aquí.
Dicho esto, mostramos un ejemplo de cómo codificarlos:

¡A que mola! Tan sólo tenemos que asignar la sintaxis a una variable y usar ésta para reproducir el carácter todas las veces que queramos.
Así podemos hacer cosas como:

Muy bonito, sí. Pero, ¿cómo podemos obtener los códigos que corresponden a cada signo o símbolo?
 LO PRIMERO QUE TENEMOS QUE HACER ES ABRIR EL SIGUIENTE ENLACE QUE OS DEJO AQUÍ:
LO PRIMERO QUE TENEMOS QUE HACER ES ABRIR EL SIGUIENTE ENLACE QUE OS DEJO AQUÍ:
Una vez que tengamos abierta la página navegamos por ella pendientes de las categorías para saber dónde encontrar el signo o símbolo que buscamos. Cuando la hayamos encontrado, pulsamos sobre la imagen. Se nos abrirá un cuadro explicativo con cuatro opciones. A nosotros nos interesa la última, la que comienza con alert():. A partir de aquí, copiamos el texto que se muestra a la derecha y se lo asignamos a la variable que hayamos declarado en nuestro código. ¡Voilà! Ya está todo hecho:


Podemos realizar múltiples combinaciones entre índices y otros objetos apoyándonos en los OPERADORES DE LAS STRING + y *. Esto es posible porque al fin y al cabo, un índice identifica un carácter literal que, en sí mismo, no deja de ser una string de len(string) = 1.
¡Cuántas combinaciones podemos hacer "jugando" con los índices para entresacar palabras con sentido, ¿verdad?! O sin él, si no nos importa que tengan o no significado, salvo que juguemos al SCRABBLE. Lo que nos importa es que podamos comprobar de manera fehaciente las posibilidades que nos brinda el trabajo con índices: podemos sumarlos; combinarlos con otras strings, bien sin estar asignadas a variables, como "MELO", o estándolo como b = "MOR"; hemos usado el operador * para repetir caracteres;...
Para este último caso hemos utilizado paréntesis para englobar a aquellos índices que queremos repetir. Es necesario en el caso de CACATÚA porque si solo escribimos a[4] + a[-6] * 2 + ... sólo nos repite dos veces la 'A'. En el caso de LLAVE no es necesario usar paréntesis pues sólo toca duplicar un carácter, a[-3], la 'L'.
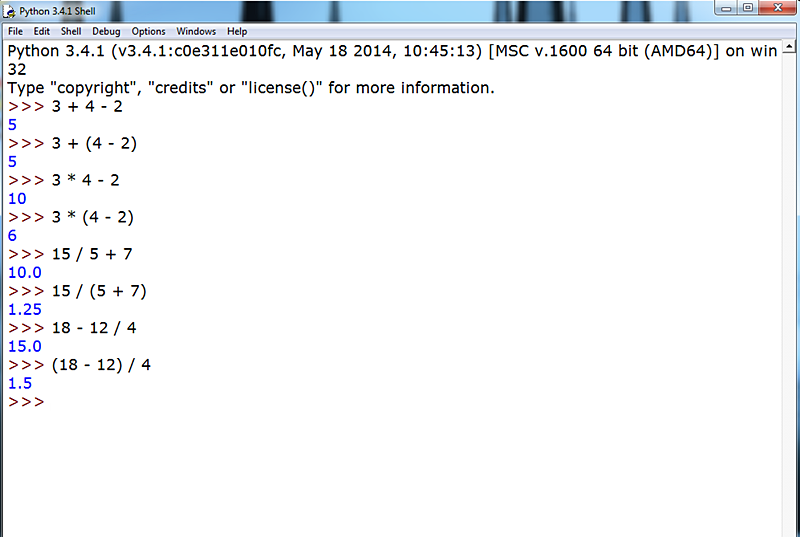
Tengamos en cuenta, y esto es una norma universal en aritmética y que también, como no puede ser menos, Python aplica escrupulosamente, las preeminencias de las operaciones: la multiplicación primero, luego la división, la suma y, finalmente, la resta:
Permitámonos aquí una pequeña "disgresión aritmética", aunque éste no sea el capítulo dedicado, para ilustrarnos en el asunto y aprovechar, de paso, para repasar un poco el tema de ARITMÉTICA BÁSICA. Solo serán unas pocas expresiones:
Con este ejemplo que acabamos de ver nos podemos hacer una idea de las preeminencias de los operadores en las expresiones matemáticas donde, con los mismos operadores y los mismos números, los resultados que se obtienen pueden ser radicalmente distintos.
Regresemos a nuestros índices.
Si queremos almacenar en una variable cualquiera nuestras "carreras" de índices lo podemos hacer perfectamente y sin problemas. Así podríamos utilizarlas más adelante si quisiéramos. Aquí tenemos un ejemplo:
Reparemos, por cierto, en que cuando hemos declarado la variable 'y' con su valor "TIENE", lo hemos hecho dejando un espacio en blanco entre las comillas, antes de la "T" y después de la "E" final. De este modo, cuando la variable 'f' nos devuelva el resultado, las tres palabras aparecerán correctamente separadas y no concatenadas como 'CARLOSTIENECALOR'. Insistimos: si no queremos ver las comillas en el resultado podemos incluir la variable 'f' entre los paréntesis de la función print() y problema resuelto. Eso sí, sólo tendremos una presentación puramente cosmética, sin relevancia alguna desde el punto de vista de la codificación.
Un aspecto a destacar es el comportamiento de las cadenas con respecto a los operadores de comparación. Si comparamos dos strings mediante los operadores < y >, respectivamente, "menor que" y "mayor que", Python orientará la devolución de acuerdo al orden alfabético, de tal modo que una posición más alta de una letra con respecto a otra hace que la primera sea menor que la segunda, y viceversa. Así pues, "h" será menor que "t" pero mayor que "c", donde "a" será siempre la menor y "z" la mayor. Los números, pasados como strings, son menores que las letras, y se considera a las minúsculas mayores que las minúsculas, independientemente de su orden alfabético (una "a" minúscula es mayor que una "Z" mayúscula). Veamos un ejemplo para aclararnos con el batiburrillo éste:
SLICE, que en castellano significa "REBANADA". No. No se trata de rebanadas de pan con miel, ni con dorado aceite de oliva español (y olé), ni con tomate, ni mantequilla, ni con náa. Perdón por la majadería pero es que la tenía a ... No. Se trata de trabajar con índices casi tal cual como hemos venido haciendo hasta ahora, sólo que esta vez, vamos a trabajar con dos: un ÍNDICE INICIAL y un ÍNDICE FINAL.
Del mismo modo que a la técnica de señalar un índice para un carácter determinado dentro de una cadena de caracteres se denomina INDEXACIÓN, la técnica de creación de una slice o rebanada entre dos índices dados se denomina, en inglés, SLICING.
De esta manera, al igual que ocurre en el caso de los índices obteníamos subcadenas o substrings constituidas por un único carácter literario (por ejemplo, de la string "HOLA" podíamos obtener el índice 0, para lo que le asignamos una variable y así poder trabajar con ella con más facilidad, x mismo, y hacemos la preceptiva declaración de asignación, hagamos memoria de lo que hemos estudiado, tal que x = "HOLA". Ahora insertamos entre corchetes el índice 0 con la sintaxis que nos exige Python, x[0] en la siguiente línea de código, y obtenemos la H, que es una substring de HOLA con lo puede ser LA, OLA, O, etc. Todos los fraccionamientos que podamos conseguir con ella), con las slices o rebanadas vamos a obtener substrings con dos o más caracteres literarios. También podríamos obtener una substring de un único carácter literario, igual que un ÍNDICE pero, precisamente, para eso están los índices, ¿pasa algo?
Vamos a verlo con un ejemplo:
Vamos a fijarnos ahora en unos cuantos detalles que nos ayudarán a comprender la dinámica de las rebanadas. En primer lugar, su sintaxis. el cómo tenemos que declararlas para que el intérprete de Python nos entienda. Como a fin de cuentas seguimos trabajando con índices recurrimos a una sintaxis muy similar a la que ya conocemos: la variable 'a' primero y, a la derecha, los corchetes, [], sólo que en esta ocasión, como ya hemos comentado antes, con dos índices, el índice de inicio, el 'DESDE', que es aquél que determina el carácter literario por el que comenzamos a contar (la primera rebanada del pan, para hacernos una idea); y el índice final, 'HASTA', que es aquél otro con el que terminamos de contar (la segunda rebanada del pan), separados uno del otro por dos puntos, ':'.
Así que cuando pedimos un resultado cuando codificamos una slice o rebanada (las rebanadas del pan), Python nos devuelve la "chicha", el "embutido", lo que queda entre las dos rebanadas. Lo pillamos, ¿no? Si el índice de inicio es 0, luego, "C", y el índice final es 7, luego, "A", la "chicha", el "embutido", lo que queda entre uno y otro, es 'CARACOL'.
¡CUIDADO! Un detalle importante: el índice final no es tenido en cuenta por Python. Por eso el resultado que hemos obtenido en nuestro ejemplo no es CARACOLA sino CARACOL. Hay que tenerlo muy, muy, presente a la hora de obtener las substrings que nos interesan.
Ya se sabe que las rebanadas las carga el diablo.
También, como es de esperar, podemos obtener el resultado que nos interesa usando índices negativos, es decir, leyendo de derecha a izquierda, y siempre teniendo en cuenta que el índice final, como ya sabemos, no es leído por Python. Fijémonos que para obtener el resultado 'CARACOL', como leemos de izquierda a derecha, empezamos por el índice menor que será nuestro índice de inicio, y concluimos con el índice mayor, aquél que está más cerca de 0, que será nuestro índice final.

Veamos lo siguiente: "buenos días" tiene para Python 11 caracteres, de los cuales 10 son literales y uno es un espacio en blanco que separa ambas palabras y que cuenta también como carácter literal, todos estos de longitud 1. La suma de todos ellos, como ya hemos dicho, es de 11 caracteres.
Y esto lo podemos comprobar llamando o invocando a una nueva función nativa de Python, como lo son print() o type(): la función len() que nos dice la cantidad exacta de caracteres literales que componen una string. Procedamos a aplicarla a nuestro ejemplo:
 |
La función len() es la contracción del término inglés 'length', "longitud", en castellano, que ya nos proporciona una idea de lo que hace esta función. Observemos que lo único que tenemos que pasar como argumento de la función es la propia string o, hagamos memoria, el nombre o identificador que referencia un espacio en la memoria que alberga un dato, en este caso, de tipo string. Sí, sí, que sí: la variable que contiene a la string.
 |

Hagamos una precisión importante: cuando queramos introducir un texto previamente entrecomillado, como por ejemplo, una acotación o una cita, debemos tener en cuenta que no podemos repetir el tipo de comillas: si optamos por iniciar una string con comillas dobles ("double quotes"), en el momento que vayamos a introducir la cita debemos recurrir a las comillas simples ("single quotes") porque, de lo contrario, Python entenderá que la string termina aquí, continuar con el texto y, efectivamente, cerrar nuestra cadena tal cual como la hemos empezado: con comillas dobles.
Ilustremos el caso con un ejemplo:
 |
 |
En la detección del error, Python nos subraya la palabra 'Leoncitos' (podemos hablar de substrings, partiendo de la base de que una substring puede entenderse como una porción de una string, habitualmente y de cara al programador humano, aquellas porciones que tengan un significado por sí mismas como, por ejemplo, una palabra, un subtexto, un título, etc., en nuestro ejemplo, 'Leoncitos', básicamente, porque cuando escribimos un texto pretendemos que se muestre en pantalla y que éste sea leído y comprendido por otro/s ser/es humanos, por lo que dicho texto está conformado a su vez por distintos elementos legibles y comprensibles para nosotros como sustantivos, pronombres, verbos, adjetivos, etc. que constituyen los 'ladrillos' con los que componemos los textos de nuestro idioma, igual y necesariamente legibles y comprensibles, y es precisamente en estos 'ladrillos', como lo es el sustantivo 'Leoncitos' con los que solemos trabajar cuando introducimos texto en nuestros códigos para construir correctamente esos mismos textos. Sin embargo, también son substrings en última instancia cualquier carácter literario que forme parte de otro mayor sea cual sea la longitud del primero siempre y cuando no supere la longitud (len()) menos 1 (al menos) de la string de la que forma parte: 'L' es una substring de 'Leoncitos'; 'onci', también; 'tos', también; 'Leoncito', también; pero 'Leoncitos' no porque no es la longitud de la string menos 1, sino que muestra una longitud similar a la de la string que lo contiene, luego es la propia string y no una substring propiamente dicha). Así el intérprete de Python nos señala dónde se encuentra el yerro y desde dónde empieza.
Por cierto, y enlazando con lo que comentábamos unos párrafos más arriba, aquí no se lanza ninguna excepción del tipo Traceback. No hay ningún "rastreo de error". ¿Por qué? Porque Python detecta el error justo cuando cerramos la línea de código que estamos escribiendo y pulsamos ENTER para escribir una nueva. Se trata casi siempre de errores ortográficos (¡ay, que no le pusimos la tilde a 'ortograficos', por ejemplo) que no demandan la ejecución de un programa, y errores de sintaxis (¡ay, que pusimos el artículo después del sustantivo en 'pelota la', por ejemplo), antes que errores gramaticales que sí suelen advertirse cuando se demanda la ejecución del mismo.
En resumidas cuentas, cuando vamos a introducir una acotación o una cita:
- (" ') sí
- (" ") no
- (' ") sí
- (' ') no
 |
Veamos qué nos devuelve la función str() en función de los argumentos que le pasemos:
- str( ) => Sin argumentos devuelve una cadena vacía, " ".
- str(dato != string) => Si el dato es distinto a una cadena lo convierte a cadena
- str(string) => Si el dato es una string devuelve una COPIA de la cadena
La función str() puede recibir dos argumentos opcionales que deben ser pasados como cadenas: uno especifica la codificación mientras que el otro determina cómo deben manejarse los errores de codificación. Esto no nos interesa de momento y lo mostramos aquí tan sólo a título informativo:
 |
 |
| LA ISLA DE LA GOMERA VISTA DESDE LA FORTALEZA DE MASCA, OESTE DE TENERIFE |
T2. CODIFICACIONES DE CARÁCTER. LA UNIÓN HACE LA FUERZA.
Ver la siguiente entrada:
T1. OPERADORES DE LAS STRING. TAMBIÉN TIENEN DERECHO.
CARACTERES ESPECIALES Y SÍMBOLOS ASCII EN PYTHON:
Obviamente, cuando escribimos una string (y, por extensión, cuando escribimos cualquier cosa en nuestro ordenador, ya sea un documento de texto, codificamos un programa, introduzcamos nuestros datos en un formulario en un sitio web, etc.), lo hacemos de manera habitual a través del teclado, ése gran desconocido que tanto nos da y tan poca importancia damos. Aquí encontramos la mayor parte de los caracteres literales de nuestro idioma, siempre y cuando estemos usando uno adaptado de forma específica al nuestro propio, por ejemplo, un teclado para hispanohablantes debe contener la 'ñ', mientras que para los que sólo usan el inglés, el carácter 'ñ' es inútil, y los dígitos, del 0 al 9, que necesitamos para expresarnos. Además, contiene una serie de signos y símbolos de uso común, como =, + , @, (, /, *, ·, etc. a los que podemos acceder, o bien directamente, pulsando la tecla correspondiente, o bien indirectamente, mediante una combinación de las mismas.
Como ya sabemos, por eso todos los lenguajes de programación habidos y por haber, para facilitarnos las cosas a nosotros, sufridos programadores, utilizan estos mismos signos, sólos o en combinación con otros, como operadores de todo tipo, cuantificadores, limitadores, etc por su universalidad y su fácil acceso.
Pero... ¿qué sucede con ciertos signos y símbolos que nos gustaría emplear en nuestros programas y no se encuentran entre nuestras opciones predeterminadas de teclado? ¿Qué pasa con el símbolo de la raíz cuadrada? ¿Y el de exponenciación al cuadrado? ¿Dónde diantre está la sigma mayúscula griega que apunta al sumatorio total matemático? Y ya que estamos, ¿Y si queremos usar caracteres del alfabeto griego, por ejemplo, para senos, cosenos, tangentes y otras lindezas trigonométricas?...
Veamos esta captura:

¿Cómo hemos conseguido que se muestren esos signos de exponenciación y raíz en la calculadora del ejemplo?
Pues haciendo uso de los caracteres ASCII correspondientes.
¡Ah!... ¿Y cómo podemos implementarlos en nuestro código para que, por ejemplo, se muestren en pantalla cuando ejecutemos un print()?
Llamándolos mediante una sintaxis propia que responde al siguiente formato: "\uxxxx", donde a partir de \u cada x, hasta un máximo de cuatro, se corresponde con una secuencia alfanumérica que, en la mayor parte de los casos, comienza en 2. También es posible encontrar otra modalidad, "\xxx", que apunta a ciertos símbolos y caracteres especiales ASCII. Es posible hallar algún otro formato sintáctico más, según lo que vayamos buscando, pero la mayoría de los más usuales se atienen a la sintaxis que mostramos aquí.
Dicho esto, mostramos un ejemplo de cómo codificarlos:

¡A que mola! Tan sólo tenemos que asignar la sintaxis a una variable y usar ésta para reproducir el carácter todas las veces que queramos.
Así podemos hacer cosas como:

Muy bonito, sí. Pero, ¿cómo podemos obtener los códigos que corresponden a cada signo o símbolo?
Signos y símbolos ASCII
Una vez que tengamos abierta la página navegamos por ella pendientes de las categorías para saber dónde encontrar el signo o símbolo que buscamos. Cuando la hayamos encontrado, pulsamos sobre la imagen. Se nos abrirá un cuadro explicativo con cuatro opciones. A nosotros nos interesa la última, la que comienza con alert():. A partir de aquí, copiamos el texto que se muestra a la derecha y se lo asignamos a la variable que hayamos declarado en nuestro código. ¡Voilà! Ya está todo hecho:


 |
| PANORÁMICA DE LA VILLA DE EL SAUZAL, Y COSTA NORTE DE TENERIFE. |
INDEXACIÓN DE LAS STRINGS
Las strings, nuestras cadenas de texto, pueden ser indexadas. ¿Qué significa esto? Tan sólo que las strings pueden ser ordenadas de acuerdo a un índice numerado, como los capítulos de un libro, por ejemplo. Recordemos que una string es, sucíntamente, una cadena de caracteres literales donde cada eslabón es un único carácter, incluidos los espacios en blanco, de longitud 1, y que lo son porque los encerramos entre comillas que, a su vez, construye un texto, tenga o no significado para nosotros, pues tan string es esta cadena, con un significado evidente para nosotros, "HOLA", como ésta otra, "HoLa", y ésta "rf55yjig#FF", a pesar de su tremendo sinsentido: lo que cuenta son las comillas, no lo olvidemos.
Pues bien, a cada uno de estos caracteres se les puede asignar un número que los identifica en un orden determinado, en el caso de Python, si lo hacemos de izquierda a derecha, en orden creciente, con números positivos y empezando desde 0; y si lo hacemos al contrario, de derecha a izquierda, en orden decreciente y con números negativos.
Vamos a verlo mucho más claro con el ejemplo que traemos a continuación. Tomamos para ello como base la palabra CARAMELO:
 Así por ejemplo, el número 3 apunta, leyendo de izquierda a derecha, al carácter A. O que el número 6 indexa del mismo modo al carácter L. sin embargo, este mismo carácter literal, L, se identifica leyendo de derecha a izquierda, en sentido contrario, con el número -2. ¿A que ahora lo entendemos un poquito mejor?
Así por ejemplo, el número 3 apunta, leyendo de izquierda a derecha, al carácter A. O que el número 6 indexa del mismo modo al carácter L. sin embargo, este mismo carácter literal, L, se identifica leyendo de derecha a izquierda, en sentido contrario, con el número -2. ¿A que ahora lo entendemos un poquito mejor?
Para indexar una string es necesario primero declararla con una variable. Una vez que lo hayamos hecho, utilizamos la siguiente sintaxis: Nombre_de_la_variable[número]. Dentro de los corchetes debemos introducir un número entero, positivo o negativo, al que llamamos ÍNDICE (o INDEX, en inglés). Python nos devolverá entonces el carácter literal de la string al que corresponda dicho índice, de izquierda a derecha si nuestro número es un entero positivo, o de derecha a izquierda si nuestro número es un entero negativo.
Tengamos en cuenta que al primer carácter de izquierda a derecha le corresponde el índice 0, mientras que al primer carácter de derecha a izquierda le corresponde el -1, y no el -0, que ni tiene sentido (es una aberración matemática: algo que no existe no puede ser ni positivo ni negativo. Tan sólo no es), ni es admitido por Python, ni falta que le hace.
Ejemplo al canto:
Hemos recurrido a la función print() para comprobar que podemos recibir un índice dentro de la propia función y evitarnos así las comillas. Para x[3] podemos ver cómo Python nos devuelve un carácter vacío puesto que, como ya sabemos, cada espacio vacío cuenta como un literal: a 'D' le corresponde el índice 0, a 'o' le corresponde el 1, a 'n' el 2 y al siguiente carácter, el siguiente eslabón en la cadena, que es un carácter vacío, ' ', le corresponde el 3.
Como podemos deducir todo carácter tiene, realmente, dos índices que lo señalan, uno positivo, insistimos, si leemos de izquierda a derecha, y un índice negativo si lo hacemos desde el lado contrario:
Pues bien, a cada uno de estos caracteres se les puede asignar un número que los identifica en un orden determinado, en el caso de Python, si lo hacemos de izquierda a derecha, en orden creciente, con números positivos y empezando desde 0; y si lo hacemos al contrario, de derecha a izquierda, en orden decreciente y con números negativos.
Vamos a verlo mucho más claro con el ejemplo que traemos a continuación. Tomamos para ello como base la palabra CARAMELO:

Para indexar una string es necesario primero declararla con una variable. Una vez que lo hayamos hecho, utilizamos la siguiente sintaxis: Nombre_de_la_variable[número]. Dentro de los corchetes debemos introducir un número entero, positivo o negativo, al que llamamos ÍNDICE (o INDEX, en inglés). Python nos devolverá entonces el carácter literal de la string al que corresponda dicho índice, de izquierda a derecha si nuestro número es un entero positivo, o de derecha a izquierda si nuestro número es un entero negativo.
Tengamos en cuenta que al primer carácter de izquierda a derecha le corresponde el índice 0, mientras que al primer carácter de derecha a izquierda le corresponde el -1, y no el -0, que ni tiene sentido (es una aberración matemática: algo que no existe no puede ser ni positivo ni negativo. Tan sólo no es), ni es admitido por Python, ni falta que le hace.
Ejemplo al canto:
 |
Como podemos deducir todo carácter tiene, realmente, dos índices que lo señalan, uno positivo, insistimos, si leemos de izquierda a derecha, y un índice negativo si lo hacemos desde el lado contrario:
 |
Sin embargo, observemos este caso:
¿Qué ha pasado? En el primer caso nos ha saltado un mensaje de error. Python ha encontrado una EXCEPCIÓN en el proceso de ejecución. La tercera línea nos avergüenza con nuestro yerro, x[-24], y la última nos lo aclara: IndexError: ¡vaya! El error está en el indexado; string index out of range, que quiere decir que el índice de la string queda fuera del largo de la cadena, fuera de su "length". Sin embargo, cuando buscamos el índice de derecha a izquierda y tornamos, pues, 24 en -24, Python nos devuelve un resultado correcto: 'D'. Como ya nos habremos dado cuenta, esto sucede porque contando de izquierda a derecha, el índice inicial no es 1 sino 0, por lo que el último índice que corresponde al carácter final de la string es 23 y no 24, mientras que por el lado opuesto, de derecha a izquierda, como al primer índice por la derecha le corresponde el -1, al último de la cadena en el extremo izquierdo, a la 'D' le corresponde el -24.

 |

Para tener acotados los índices de una string, sobre todo cuando contienen un número considerable de caracteres, podemos recurrir a una función preconstruida o nativa de Python que ya nos resulta familiar: len() que nos devuelve la cantidad total de caracteres de una string. Y sabremos que el índice final de la misma, aquél que señala al último eslabón de la cadena de literales, contando de izquierda a derecha, será el resultado de la expresión len(variable) - 1: el número resultante de restarle 1 a la longitud total de la cadena.
¡Guau! ¡Qué fácil,
¡Guau! ¡Qué fácil,
 |
 |
 |
| BALCONADA TÍPICA EN RUINAS, CASERÍO DE IFONCHE, VILAFLOR, SUR DE TENERIFE. S |
¡Cuántas combinaciones podemos hacer "jugando" con los índices para entresacar palabras con sentido, ¿verdad?! O sin él, si no nos importa que tengan o no significado, salvo que juguemos al SCRABBLE. Lo que nos importa es que podamos comprobar de manera fehaciente las posibilidades que nos brinda el trabajo con índices: podemos sumarlos; combinarlos con otras strings, bien sin estar asignadas a variables, como "MELO", o estándolo como b = "MOR"; hemos usado el operador * para repetir caracteres;...
Para este último caso hemos utilizado paréntesis para englobar a aquellos índices que queremos repetir. Es necesario en el caso de CACATÚA porque si solo escribimos a[4] + a[-6] * 2 + ... sólo nos repite dos veces la 'A'. En el caso de LLAVE no es necesario usar paréntesis pues sólo toca duplicar un carácter, a[-3], la 'L'.
Tengamos en cuenta, y esto es una norma universal en aritmética y que también, como no puede ser menos, Python aplica escrupulosamente, las preeminencias de las operaciones: la multiplicación primero, luego la división, la suma y, finalmente, la resta:
- EXPRESIONES ARITMÉTICAS ENTRE PARÉNTESIS
- POTENCIAS Y RAÍCES
- MULTIPLICACIONES Y DIVISIONES
- SUMAS Y RESTAS
Permitámonos aquí una pequeña "disgresión aritmética", aunque éste no sea el capítulo dedicado, para ilustrarnos en el asunto y aprovechar, de paso, para repasar un poco el tema de ARITMÉTICA BÁSICA. Solo serán unas pocas expresiones:
 |
Regresemos a nuestros índices.
Si queremos almacenar en una variable cualquiera nuestras "carreras" de índices lo podemos hacer perfectamente y sin problemas. Así podríamos utilizarlas más adelante si quisiéramos. Aquí tenemos un ejemplo:
 |
Un aspecto a destacar es el comportamiento de las cadenas con respecto a los operadores de comparación. Si comparamos dos strings mediante los operadores < y >, respectivamente, "menor que" y "mayor que", Python orientará la devolución de acuerdo al orden alfabético, de tal modo que una posición más alta de una letra con respecto a otra hace que la primera sea menor que la segunda, y viceversa. Así pues, "h" será menor que "t" pero mayor que "c", donde "a" será siempre la menor y "z" la mayor. Los números, pasados como strings, son menores que las letras, y se considera a las minúsculas mayores que las minúsculas, independientemente de su orden alfabético (una "a" minúscula es mayor que una "Z" mayúscula). Veamos un ejemplo para aclararnos con el batiburrillo éste:
 |
 |
| TERRAZAS ABANCALADAS Y CASTAÑOS EN LOS ALTOS DE SANTA ÚRSULA, COMARCA DE ACENTEJO, NORESTE DE TENERIFE |
SLICES (REBANADAS)
SLICE, que en castellano significa "REBANADA". No. No se trata de rebanadas de pan con miel, ni con dorado aceite de oliva español (y olé), ni con tomate, ni mantequilla, ni con náa. Perdón por la majadería pero es que la tenía a ... No. Se trata de trabajar con índices casi tal cual como hemos venido haciendo hasta ahora, sólo que esta vez, vamos a trabajar con dos: un ÍNDICE INICIAL y un ÍNDICE FINAL.
Del mismo modo que a la técnica de señalar un índice para un carácter determinado dentro de una cadena de caracteres se denomina INDEXACIÓN, la técnica de creación de una slice o rebanada entre dos índices dados se denomina, en inglés, SLICING.
De esta manera, al igual que ocurre en el caso de los índices obteníamos subcadenas o substrings constituidas por un único carácter literario (por ejemplo, de la string "HOLA" podíamos obtener el índice 0, para lo que le asignamos una variable y así poder trabajar con ella con más facilidad, x mismo, y hacemos la preceptiva declaración de asignación, hagamos memoria de lo que hemos estudiado, tal que x = "HOLA". Ahora insertamos entre corchetes el índice 0 con la sintaxis que nos exige Python, x[0] en la siguiente línea de código, y obtenemos la H, que es una substring de HOLA con lo puede ser LA, OLA, O, etc. Todos los fraccionamientos que podamos conseguir con ella), con las slices o rebanadas vamos a obtener substrings con dos o más caracteres literarios. También podríamos obtener una substring de un único carácter literario, igual que un ÍNDICE pero, precisamente, para eso están los índices, ¿pasa algo?
Vamos a verlo con un ejemplo:
 |
Vamos a fijarnos ahora en unos cuantos detalles que nos ayudarán a comprender la dinámica de las rebanadas. En primer lugar, su sintaxis. el cómo tenemos que declararlas para que el intérprete de Python nos entienda. Como a fin de cuentas seguimos trabajando con índices recurrimos a una sintaxis muy similar a la que ya conocemos: la variable 'a' primero y, a la derecha, los corchetes, [], sólo que en esta ocasión, como ya hemos comentado antes, con dos índices, el índice de inicio, el 'DESDE', que es aquél que determina el carácter literario por el que comenzamos a contar (la primera rebanada del pan, para hacernos una idea); y el índice final, 'HASTA', que es aquél otro con el que terminamos de contar (la segunda rebanada del pan), separados uno del otro por dos puntos, ':'.
Así que cuando pedimos un resultado cuando codificamos una slice o rebanada (las rebanadas del pan), Python nos devuelve la "chicha", el "embutido", lo que queda entre las dos rebanadas. Lo pillamos, ¿no? Si el índice de inicio es 0, luego, "C", y el índice final es 7, luego, "A", la "chicha", el "embutido", lo que queda entre uno y otro, es 'CARACOL'.
¡CUIDADO! Un detalle importante: el índice final no es tenido en cuenta por Python. Por eso el resultado que hemos obtenido en nuestro ejemplo no es CARACOLA sino CARACOL. Hay que tenerlo muy, muy, presente a la hora de obtener las substrings que nos interesan.
Ya se sabe que las rebanadas las carga el diablo.
 |
También, como es de esperar, podemos obtener el resultado que nos interesa usando índices negativos, es decir, leyendo de derecha a izquierda, y siempre teniendo en cuenta que el índice final, como ya sabemos, no es leído por Python. Fijémonos que para obtener el resultado 'CARACOL', como leemos de izquierda a derecha, empezamos por el índice menor que será nuestro índice de inicio, y concluimos con el índice mayor, aquél que está más cerca de 0, que será nuestro índice final.
 |
También podemos conseguir el mismo resultado combinando índices positivos y negativos.
 |

Voy a ladrar una cosa que me he enterado. Tal y como sucede con los índices, también podemos efectuar operaciones de concatenación y repetición con los operadores + y * que tomamos prestado de los OPERADORES ARITMÉTICOS. Me he traído un ejemplo entre las patitas para que lo veamos:
 |
Atendiendo a esta peculiaridad de las slices donde el índice de inicio está incluido siempre mientras que se excluye siempre el del final, la concatenación (+) de [...:n] y [n:...]. donde n es un índice cualquiera contenido en la string y '...' un espacio vacío, nos devolverá siempre la string completa:
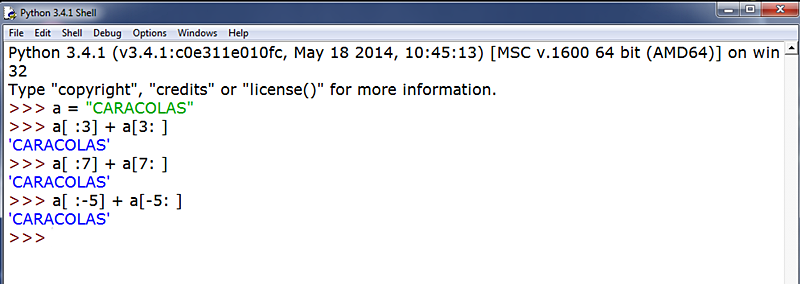 |
Este ejemplo nos permite consignar alguna propiedad más de las rebanadas. Por una parte, tenemos lo que el mismo ejemplo nos muestra: que una rebanada puede no tener el índice de inicio o el índice final. En estos casos, cuando hacemos una ELIPSIS ("ELLIPSIS", en inglés, que así se llama técnicamente un acto de omisión voluntario) de uno u otro, el intérprete de Python considera que cuando el que se omite es el índice de inicio debe escribir todos los índices desde el principio, partiendo del índice 0 que, como ya sabemos, identifica al primer carácter de la cadena; mientras que cuando el que se omite es el índice del final, el intérprete de Python escribirá todos los caracteres literarios que restan desde el índice de inicio hasta completar la string.
Apretando todavía más las tuercas, una slice de una string sin índice de inicio ni índice final, esto es, con los índices elipsados, lo que se llama una SLICE VACÍA, como podemos presuponer, nos devuelve la string original completa:
Veamos también algunos ejemplos de ELIPSIS:
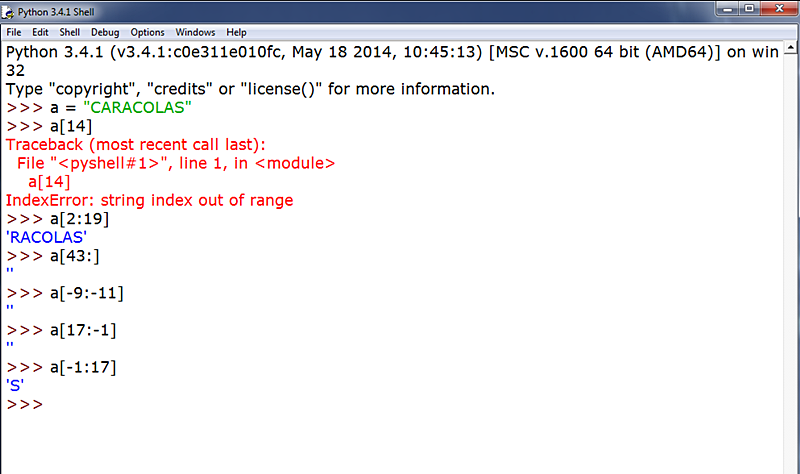
Por otra parte, cuando la identificación de un índice excede el límite (rango) de la string, Python nos da error. Sin embargo, en el caso de las rebanadas, Python devuelve resultados lógicos de acuerdo a la información que hemos introducido en ella:
En resumidas cuentas, una slice o rebanada constituye una forma sincrética de escoger un trozo de una string (en realidad, de cualquier secuencia) sin necesidad de llamar uno por uno a los índices de cada uno de ellos, y gestionarlo como una unidad, como un único carácter indexable. Más o menos, como mostramos en este esquema:
str[1:6] ··········> str[1] + str[2] + str[3] + str[4] + str[5]
Ver la siguiente entrada:
T3. IDLE DE PYTHON 1.
Hora de prácticas:

T4. BLOQUE DE EJERCICIOS 1.
Una característica común entre índices y slices es que ambos admiten expresiones matemáticas entre los corchetes, teniendo en cuenta que, como ya sabemos, Python es capaz de prever el resultado de la ejecución de un algoritmo: en ciertos casos, y éste es uno de ellos, para Python 4, 2 + 2, 2 * 2 o 8 / 2 es lo mismo. Veámoslo:
Para terminar con este extenso apartado añadimos un apunte más: las slices admiten un tercer argumento, opcional, que debe ser igualmente un número entero, y que indica cada cuántos caracteres debe contar, de tal modo que si introducimos un 2, Python devolverá la rebanada que le hemos solicitado pero mostrando sólo los caracteres de dos en dos; si introducimos un 3, hará lo propio contando de tres en tres: Ejemplo al canto:
Tenemos también la opción de introducir dos veces los dos puntos entre los corchetes: si colocamos los dos puntos y, a la derecha, un número entero, Python nos mostrará siempre el primer carácter literal de la string, y a partir de ahí contará de tanto en tanto, según sea el número entero que hayamos introducido. Es como si hubiéramos elipsado los índices de inicio e índice final y hubiéramos dejado tan sólo el argumento opcional. Si colocamos un entero negativo, nos devolverá la slice del revés. Con dos enteros entre los dobles dos puntos, el primer entero será el índice de inicio mientras que el segundo será el opcional, el que marca de cuánto en cuánto debe contar. Con un índice de inicio y los dos dobles puntos sin ningún otro entero más, sin argumento opcional, Python buscará el carácter indexado y mostrará el resto de la string a partir de aquí:
A las strings se las puede pasar como argumentos de dos funciones preconstruidas muy básicas, min(string) y max(string), donde la primera nos devolverá el carácter literal más próximo al principio del alfabeto (más cerca de 'a'), o en el caso de que nuestra cadena estuviera compuesta exclusívamente por números, el más pequeño; la segunda, por el contrario, nos devolverá el carácter literal más alejado del inicio del alfabeto (más cerca de 'z'), o en el caso de que nuestra cadena estuviera compuesta exclusívamente por números, el más grande. Por otra parte, siendo fiel al case sensitive, Python entenderá que entre dos letras iguales con distinto case, la mayúscula será menor que la minúscula. En el ejemplo, incluimos otras posibilidades:
Finalizamos con el aviso de nueva entrada, que configuramos como T4, para que la consultemos cuando ya tengamos cierto recorrido con los fundamentos básicos del programa, y en la que veremos las funciones de tipo f (f, de "format") que trabajan con cadenas y/o representaciones como cadenas, strings, de devoluciones de datos. Veremos que tienen mucho que ver con el método str.format() de las strings que aprenderemos en el siguiente apartado de este manual.
T4. LAS FUNCIONES DE TIPO F: ENCADENADOS DE POR VIDA.

PARA ACABAR, OS TRAIGO UN PEQUEÑO TRUCO QUE SE ME HA OCURRIDO A MÍ SÓLO. SE TRATA DE UN MÉTODO MNEMOTÉCNICO SENCILLO QUE NOS PERMITE SABER, A PARTIR DE LAS CARACTERÍSTICAS DE LAS REBANADAS, CUÁNTOS CARACTERES LITERALES NOS VA A DEVOLVER UNA slice: SE TRATA TAN SÓLO DE RESTAR AL VALOR DEL NÚMERO DEL ÍNDICE FINAL EL VALOR DEL NÚMERO DEL ÍNDICE DE INICIO. Y YA ESTÁ. SENCILLITO, ¿NO?
a = "pelusa"
a[2:5] => 5 - 2 = 3 (Tres caracteres)
'lus'
len(a[2:5])
3

Existe un sitio web que nos permite de forma muy sencilla (pero que muy sencilla, la verdad) de introducir como strings, como cadenas de caracteres literales, signos (glifos) que no son tan comunes en nuestros teclados y que muchas veces no sabemos dónde buscar. A pesar de que contamos con el auxilio de http://w3.unpocodetodo.info/utiles/glyphs.php, un espacio excelente donde encontrar una gran variedad de ellos e insertarlos cómodamente con sólo incluir en nuestra línea de código su formato ASCII correspondiente, este sitio web al que hago referencia nos permite insertar directamente un puñado de glifos, los más usuales, con sólo hacer clic con el botón izquierdo del ratón, lo que automáticamente, genera una copia sobre el glifo de nuestra elección y copiarlo (paste) tal cual en la línea de código, sin tener que introducir código ASCII: copiamos y pegamos. Y ya está.
El sitio web es https://www.glyphy.io/ (es simple hasta en el nombre) y, a continuación. os dejo una pequeña muestra de lo que hace. Recordemos que las comillas las tenemos que poner nosotros, claro.

Apretando todavía más las tuercas, una slice de una string sin índice de inicio ni índice final, esto es, con los índices elipsados, lo que se llama una SLICE VACÍA, como podemos presuponer, nos devuelve la string original completa:
 |
 |
Por otra parte, cuando la identificación de un índice excede el límite (rango) de la string, Python nos da error. Sin embargo, en el caso de las rebanadas, Python devuelve resultados lógicos de acuerdo a la información que hemos introducido en ella:
 |
 |
| LADERA DE GUERGUES, TENO ALTO, MACIZO DE TENO, NOROESTE DE TENERIFE. |
str[1:6] ··········> str[1] + str[2] + str[3] + str[4] + str[5]
Ver la siguiente entrada:
T3. IDLE DE PYTHON 1.
Hora de prácticas:

T4. BLOQUE DE EJERCICIOS 1.
Una característica común entre índices y slices es que ambos admiten expresiones matemáticas entre los corchetes, teniendo en cuenta que, como ya sabemos, Python es capaz de prever el resultado de la ejecución de un algoritmo: en ciertos casos, y éste es uno de ellos, para Python 4, 2 + 2, 2 * 2 o 8 / 2 es lo mismo. Veámoslo:
 |
Para terminar con este extenso apartado añadimos un apunte más: las slices admiten un tercer argumento, opcional, que debe ser igualmente un número entero, y que indica cada cuántos caracteres debe contar, de tal modo que si introducimos un 2, Python devolverá la rebanada que le hemos solicitado pero mostrando sólo los caracteres de dos en dos; si introducimos un 3, hará lo propio contando de tres en tres: Ejemplo al canto:
 |
 |
 |
| VISTA DEL TEIDE DESDE EL PINAR DEL VALLE DE LA OROTAVA |
A las strings se las puede pasar como argumentos de dos funciones preconstruidas muy básicas, min(string) y max(string), donde la primera nos devolverá el carácter literal más próximo al principio del alfabeto (más cerca de 'a'), o en el caso de que nuestra cadena estuviera compuesta exclusívamente por números, el más pequeño; la segunda, por el contrario, nos devolverá el carácter literal más alejado del inicio del alfabeto (más cerca de 'z'), o en el caso de que nuestra cadena estuviera compuesta exclusívamente por números, el más grande. Por otra parte, siendo fiel al case sensitive, Python entenderá que entre dos letras iguales con distinto case, la mayúscula será menor que la minúscula. En el ejemplo, incluimos otras posibilidades:
 |
 |
T4. LAS FUNCIONES DE TIPO F: ENCADENADOS DE POR VIDA.

PARA ACABAR, OS TRAIGO UN PEQUEÑO TRUCO QUE SE ME HA OCURRIDO A MÍ SÓLO. SE TRATA DE UN MÉTODO MNEMOTÉCNICO SENCILLO QUE NOS PERMITE SABER, A PARTIR DE LAS CARACTERÍSTICAS DE LAS REBANADAS, CUÁNTOS CARACTERES LITERALES NOS VA A DEVOLVER UNA slice: SE TRATA TAN SÓLO DE RESTAR AL VALOR DEL NÚMERO DEL ÍNDICE FINAL EL VALOR DEL NÚMERO DEL ÍNDICE DE INICIO. Y YA ESTÁ. SENCILLITO, ¿NO?
a = "pelusa"
a[2:5] => 5 - 2 = 3 (Tres caracteres)
'lus'
len(a[2:5])
3
Existe un sitio web que nos permite de forma muy sencilla (pero que muy sencilla, la verdad) de introducir como strings, como cadenas de caracteres literales, signos (glifos) que no son tan comunes en nuestros teclados y que muchas veces no sabemos dónde buscar. A pesar de que contamos con el auxilio de http://w3.unpocodetodo.info/utiles/glyphs.php, un espacio excelente donde encontrar una gran variedad de ellos e insertarlos cómodamente con sólo incluir en nuestra línea de código su formato ASCII correspondiente, este sitio web al que hago referencia nos permite insertar directamente un puñado de glifos, los más usuales, con sólo hacer clic con el botón izquierdo del ratón, lo que automáticamente, genera una copia sobre el glifo de nuestra elección y copiarlo (paste) tal cual en la línea de código, sin tener que introducir código ASCII: copiamos y pegamos. Y ya está.
El sitio web es https://www.glyphy.io/ (es simple hasta en el nombre) y, a continuación. os dejo una pequeña muestra de lo que hace. Recordemos que las comillas las tenemos que poner nosotros, claro.

 |
| CASERÍO RURAL EN TREVEJOS, COMARCA DE VILAFLOR, CENTRO OESTE DE TENERIFE |
Eres muy bueno nen
ResponderEliminarHola de nuevo, Michelle. Gracias por tu comentario. Saludos.
EliminarNo puedo dejar de felicitarlo por la forma que tiene de escribir y explicar, es muy completo sin ser aburrido, no deja lagunas en el camino, toma en cuenta todo y aclara e introduce oportunamente lo necesario para seguir avanzando con mucha seguridad. Si usted tiene hijos, seguro que tendrán grandes oportunidades, espero que encuentre la manera de que lo escuchen y valoren sus capacidades. Estoy disfrutando mucho su trabajo, por favor no deje de enseñar y escribir, su metodología es estupenda y las fotos de "SU TENERIFE" son muy relajantes y educativas.
ResponderEliminarSaludos de nuevo, sr. Tyrone. Un placer enorme encontrarlo de nuevo por aquí. Comentarios como el suyo me demuestran que ha valido la pena emprender esta aventura educativa. Gracias infinitas. Y si me lo permite, un abrazo desde mi Tenerife. Saludos.
ResponderEliminarEs estupendo, de lo mejor que he visto en la web. Gracias totales.
ResponderEliminarMuchísimas gracias por sus palabras. Espero que le resulte tan útil y eficaz como entretenido. Un placer4. Saludos.
ResponderEliminarCordial saludo. Excelente trabajo. Estoy iniciando a estudiar esta página y me ha parecido muy interesante. Muchas gracias!
ResponderEliminarMuchas gracias por su comentario, Bayron Perea. Esperamos serle lo más útil posible en sus aspiraciones. Un cordial saludo para Ud. también.
ResponderEliminarQué bien que la estoy pasando!!!! Un capítulo muy tedioso y aburrido para explicar (mucha memoria y poco razonamiento). Me imagino en una clase en la universidad, con casi todos los alumnos cabeceando o durmiendo...
ResponderEliminarPero le encontraste la vuelta, para transformarlo en una novela de suspenso, que no se pueden despegar los ojos de la pantalla.
Hace rato que no leía algo y me reía solo frente la pantalla. La parte donde explicás el ERROR, no tiene desperdicios.: " A continuación Python nos avergüenza mostrándonos sin tapujos ni anestesia la causa del error: a + b, y remata la faena señalándonos el tipo de error producido entre todos los posibles (TypeError:): " jajajaja impresionante!!!
Y el truco de tu autoría (que no se por qué no te postularon para un Nobel):
a = "pelusa"
a[2:5] => 5 - 2 = 3 (Tres caracteres)
'lus'
len(a[2:5])
3
Es digno de llamarse TEOREMA DE GAUBER.
En definitiva, sin ánimo en absoluto de burlarme del artículo, gracias a estos recursos, a parte de las ya descriptas fotos, hicieron que me "fume" de "un saque", un tema que hay que pasar, pero no es de los mas divertidos...
Gracias por tu entrega...
JR - Argentina
De nuevo, muchas gracias por tus palabras. Un placer saber que no sólo estamos acompañándote en tu aprendizaje sino que, además, conseguimos hacerlo de manera amena, amable y asequible, que era uno de los objetivos didácticos que nos planteamos al crear el blog. Dado el interés que muestras, permíteme que te recomiende encarecidamente que visites las entradas: nos consta que hay muchos visitantes quienes, a pesar de seguir el curso, apenas le dan importancia a las entradas cuando resultan FUNDAMENTALES para adquirir más conocimientos y competencias en el lenguaje. Y la verdad, es una pena. No pierdas de vista tampoco el libro que aparece bajo el epígrafe HERRAMIENTA Y UTILIDADES, en el margen superior derecho de las páginas, pues pulsando en él podrás conocer espacios web interesantísimos para aumentar y mejorar tus conocimientos. De nuevo, muchísimas gracias por su interés. Saludos cordiales.
Eliminar